Ваш город: Москва
Prescott: Последний из могикан? (Pentium 4: от Willamette до Prescott)
- Но это факт?
- Нет. Это не факт. Это больше, чем
факт. Так оно и было на самом деле.
(с) "Тот самый Мюнхгаузен"
Глава первая, в которой авторы пытаются рассказать, зачем вообще понадобилась эта статья, и в чем состоит тайный смысл ее вступления
Давно известно, что есть в мире всего три вещи, на которые человек может смотреть бесконечно долго: на бегущую воду, на горящий огонь, и на то, как другие работают. :) Не рискуя оспаривать приоритет первых двух пунктов, отметим, что в переложении для читателей ИТ - статей третья истина трансформируется в следующее утверждение: можно бесконечно долго спорить о том, "хороший" ли процессор Pentium 4, или же "плохой".
И, действительно, мало в мире процессорных архитектур, по поводу которых сломалось такое количество "копий", как по поводу микроархитектуры NetBurst, олицетворением которой служат процессоры Intel Pentium 4. Процессоры, о которых сегодня не слышал только ленивый. "Накал" этих споров не снижается и поныне, тому есть несколько причин. И то, что архитектура была объявлена в непростой для Intel момент; и то, что впервые массовые процессоры в показателях своей производительности весьма заметно зависели от того, проводилась ли оптимизация программного обеспечения под конкретную архитектуру; и то, что впервые покупатели стали непосредственными участниками "гонки мегагерц". Гонки, позднее вообще приведшей к отказу от частоты как однозначного (и сколько-нибудь адекватного) мерила производительности.
Все это, конечно же, не могло не подстегнуть жарких споров. Не стали исключением и мы: практически каждый из нас написал не одно "километровое" письмо в конференциях, отстаивая свою точку зрения. Но само разнообразие мнений говорило о том, что не все ладно в описании новой микроархитектуры. В связи с этим всеми нами было принято волевое решение: "пора положить этому конец!". Затем, немного погодя: "надо разобраться, что же собой представляет процессор Intel Pentium 4". Затем, еще немного погодя: "что-то здесь не так". Позднее стало ясно, что "не так" довольно много. Изрядно позднее зазвучали удивленные и озадаченные возгласы: "Однако!", но об этом чуть ниже.
Наступило время пояснить, кто же такие эти самые "мы". :) Возможно, читатели, интересующиеся подробностями работы процессоров, припомнят статьи про микроархитектуру процессоров AMD Athlon 64 (Opteron). И, возможно, припомнят команду, работающую над этими статьями. По крайней мере, нам хотелось бы в это верить. :) Вот эта самая команда, в несколько обновленном составе, и работала над обзором микроархитектуры Intel Pentium 4. Тем более что в процессе подготовки предыдущих статей был накоплен некоторый опыт совместной работы.
Позволим себе напомнить имена участников (в алфавитном порядке):
Вайцман Илья, известен как Stranger_NN
Керученько Ян, известен как C@t
Левченко Вадим, известен как VLev
Лыков Андрей, известен как ISA_user
Малич Юрий, известен как Yury_Malich
Павлов Игорь, известен как lkj
Романов Сергей, известен как GReY
Также встречайте новых участников "круглого стола любителей поговорить о процессорах":
Гавриченкова Илью, известного как Gavric
Загурского Сергея, известного как McZag
Таким образом, обсуждение обещало быть (да и стало) вполне интересным. Ну а результаты этого обсуждения в очередной раз позволили подвести "ни разу не любителю барабанить по клавиатуре" Картунову Виктору (он же matik). Это самый простой из известных способов заставить его сделать хоть что-то полезное. :)
Осталось добавить, что в процессе осмысливания полученных данных мы в очередной раз восхитились тому, насколько изощренной может быть фантазия инженеров – разработчиков. Итак, "welcome into Intel Pentium 4", и да помогут нам Энди Гроув и Гордон Мур, мир с ними обоими.
Глава вторая, в которой выясняется, что первая глава была совсем необязательной, а третья наверняка будет непонятной
Работая над микроархитектурой К8, мы пришли к выводу, что наиболее разумным вариантом кажется не столько дублирование существующего описания микроархитектуры непосредственно от производителя, сколько разъяснение особенностей простым и понятным языком. Кроме того, вполне привлекательной выглядит идея сосредоточиться на том, чтобы прояснять неясные места документации, либо находить нюансы, которые по тем или иным причинам в документации опущены. Безусловно, некоторые повторы и пересечения с документацией неизбежны; в конце концов, изучение любой микроархитектуры всегда будет опираться именно на документацию (если эта документация доступна).
Также необходимо отметить, что мы публикуем эту работу именно сейчас, когда многие черты микроархитектуры Pentium 4 уже давно не являются новостью. Настолько не являются, что сегодня почти каждый ИТ журналист готов объяснять "недостатки длинного конвейера при предсказании переходов", не задумываясь при этом, и не отрываясь от бутерброда. Такая намеренная задержка с публикацией вызвана несколькими причинами. Во-первых, процессор Pentium 4 в некоторых нюансах своей работы оказался весьма непрост. Во-вторых, ситуация осложнена тем, что, несмотря на одинаковое маркетинговое название "Pentium 4", в некоторых ситуациях версии ядра Northwood и Prescott сильно отличаются друг от друга своим поведением. В результате, фактически, частенько приходилось отдельно исследовать ядро Northwood, и отдельно ядро Prescott. В-третьих, хочется избежать некоего нездорового "ажиотажа" вокруг деталей микроархитектуры: мы не ставим себе цель повлиять на настроение читателей, нам интересуют технические подробности.
К тому же, после отмены проекта Tejas, стало очевидно, что Prescott – это последняя серьезная модификация ядра Pentium 4. Безусловно, вновь подымут частоту системной шины, "включат" поддержку EM64T, увеличат кэш второго уровня – но, в сущности, все это будет лишь внешними изменениями, само же ядро более не претерпит серьезных переработок. Поэтому именно сейчас имеет смысл попробовать подвести итоги: что же нам известно об этой микроархитектуре? Можно ли объяснить особенности поведения процессора Pentium 4, опираясь на нечто более существенное, нежели набившие оскомину фразы "о длинном конвейере"? Можем ли мы ответить на "простые" и "детские" вопросы вроде "какова же полная длина конвейера в Pentium 4"?
Что ж, посмотрим, к чему привели наши изыскания. Ну а поскольку процесс поиска частенько был не менее (а иногда и более) интересен, чем результат, позволим себе рассказать несколько полудетективных историй о том, как мы искали подробности. Тем более, что рассказ будет по необходимости изобиловать специфическими терминами; в силу этого некоторое [небольшое] количество "разгрузочного материала" представляется даже желательным для улучшения понимания.
Перед тем, как перейти к описанию собственно микроархитектуры, кратко напомним несколько известных вещей. Известных, но по-прежнему важных.
Не является секретом, что производительность любой процессорной микроархитектуры можно представить себе в виде произведения частоты процессора на число операций за такт. Соответственно, чем больше каждый из множителей, тем больше произведение. В идеальной ситуации было бы неплохо растить и частоту, и количество исполняемых за такт команд. Однако в реальной жизни все заметно сложнее, хоть рост частот и рост количества исполняемой за такт работы напрямую друг другу не противоречат. Рост количества исполняемых за такт команд требует специального дизайна, требует сложного анализа взаимозависимостей команд, да и частенько ограничен в силу невысокой степени возможного распараллеливания используемых алгоритмов.
С ростом частоты тоже не все так просто. Фактически, для роста частоты нам необходимо специально оптимизировать дизайн таким образом, чтобы на каждой стадии работы процессора выполнять примерно одинаковое количество работы. Если не следовать этому правилу, то, как правило, наиболее "нагруженная" ступень становится тормозом, не давая наращивать частоту. Кроме того, рост частот – это [при прочих равных условиях] всегда рост тепловыделения. В такой ситуации обычно помогает переход на более мелкие технологические нормы, но и этот источник усовершенствований не бесконечен (что особенно хорошо заметно именно сейчас, на фоне трудностей с техпроцессом 90 нм, который испытывают все крупные производители микросхем). Дело в том, что с уменьшением геометрических норм технологического производства появляются новые трудности, которые не так-то просто преодолеть.
В процессе развития х86 процессоров корпорация Intel держала курс на увеличение количества команд, исполняемых за такт. Каждое новое поколение процессоров (Pentium, Pentium Pro) могло исполнять больше команд за такт, чем предыдущее. При этом с улучшением технологического процесса обычно росла и частота процессоров. Другими словами, постепенно увеличивались оба множителя, что приводило к быстрому росту производительности. Так продолжалось до того момента, пока частотный потенциал микроархитектуры Р6 не был практически исчерпан – до есть до частоты 1400MHz. Лебединой песней этой микроархитектуры были процессоры Pentium III–S, снабженные 512КВ кэша второго уровня (не беря в расчет процессоры семейства Pentium M). Хотя уровень их производительности был весьма достойным, во многих вещах они уже уступали процессорам от конкурента. Кстати, надо отдать должное этой микроархитектуре: начинаясь с частоты 150MHz (технологический процесс 0.5 микрон, Pentium Pro 150MHz), она выросла до частоты 1400MHz при технологических нормах 0.13 микрон (вышеупомянутый Pentium III–S с частотой 1400MHz). То есть, процессоры этой микроархитектуры выросли в частоте в 9 раз, и геометрические размеры их элементов уменьшились примерно в 4 раза. Вообще говоря, мы затрудняемся назвать другую микроархитектуру, которая смогла бы похвастаться тем же.
Естественно, задолго до момента исчерпания "запаса прочности" микроархитектуры Р6 команда разработчиков работала над ее наследником. Микроархитектура получила название Net Burst, и ее ключевым отличием от предыдущей являлось то, что приоритеты изменились. Все силы разработчиков были брошены не столько на увеличение количества исполняемых за такт команд, сколько на то, чтобы на одинаковом с Р6 технологическом процессе можно было добиться как можно большей частоты. Подчеркнем, никто не стоял перед выбором "или большая производительность за такт, или высокая частота", но приоритеты в разработке отдавались прежде всего увеличению частот.
Безусловно, с маркетинговой точки зрения это был правильный выбор. Поколения пользователей, приученные к тому, что "больше" означает "лучше", кошельком подтверждали правильность оценки их приоритетов маркетинговым отделом. Но не маркетинговые нюансы сегодня интересуют нас – нас интересуют те черты микроархитектуры Net Burst, которые и сделали возможным покорение высоких частот. И следствия из этих черт.
Таким образом, будем рассматривать Pentium 4, памятуя, что ключевой особенностью всех его нововведений была необходимость наращивать частоту. То есть, любое нововведение оценивалось, прежде всего, с точки зрения полезности для роста частот.
Глава третья, в которой мы знакомимся с новыми терминами, а также вспоминаем значение многих старых терминов
Для дальнейшего разговора будет полезно припомнить схематическое устройство процессора Pentium 4: известные нам сведения о микроархитектуре Pentium 4, общие для всех поколений ядер. А дальше, при необходимости, будем уточнять, чем отличаются процессоры на ядре Willamette и Northwood от процессора на ядре Prescott. При этом мы оговоримся, что «по умолчанию» будем рассматривать ядро Northwood: как мы уже писали выше, в некоторых аспектах ядра Northwood и Prescott существенно отличаются. В частности, в ядре Prescott времена исполнения очень многих команд существенно изменились (некоторые цифры приведены в Приложении 1). Это говорит о том, что ядро было очень сильно переработано. Впрочем, это не новость, новость то, насколько сильно оно было переработано. Хотя, безусловно, характерные черты микроархитектуры NetBurst (длинный конвейер, наличие Trace cache, и так далее) легко различимы.
Итак, в ноябре 2000 года широкой публике был представлен новый процессор, Pentium 4. Вместе с ним была представлена новая парадигма, NetBurst, которая должна была решить накопившиеся к тому времени проблемы с повышением производительности. Более подробный рассказ об NetBurst отложим до следующих глав, пока же взглянем на блок-схему ядра Willamette, и сформулируем основные принципы работы отдельных блоков процессора. Отличием ядер между собой мы пока пренебрегаем (в частности, более современное ядро Northwood отличается от Willamette, в основном, технологическим процессом и объемом кэша второго уровня). Поэтому для рассмотрения общих принципов микроархитектуры Pentium 4 оно вполне подходит.
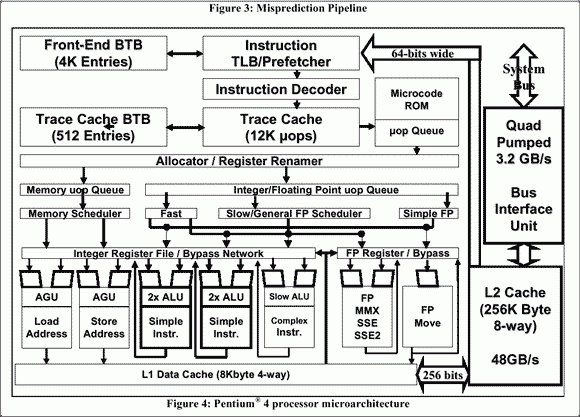
Численные значения пропускной способности шины (3.2GB/sec) и объема кэша второго уровня (256КВ) относятся к самой ранней версии процессоров Pentium 4, но для рассмотрения микроархитектуры процессора это несущественно.
Можно заметить, что микропроцессор представляет собой несколько функциональных блоков:
Группу исполнительных устройств, и обслуживающие их устройства (Back End).
2. Группу устройств, отвечающих за декодирование инструкций и своевременную их подачу первой группе (Front End). Сюда же входит группа устройств, обеспечивающих некоторые специфические возможности: блок предвыборки (prefetch), модуль предсказания переходов (Branch Prediction Unit). Эта группа, не будучи абсолютно необходимой для работы остальных групп, предназначена для повышения эффективности их работы. Назовем ее специальной группой.
Группу устройств, ведающих загрузкой и «подачей» данных в исполнительные блоки (Memory Subsystem).
Поясним смысл появившегося термина Front End, и парного ему термина Back End. Если очень упростить ситуацию, то процессор можно представить себе как комплекс, состоящий из ядра, и подсистемы памяти, ее мы уже выделили в отдельную группу. Ядро же процессора можно представить в виде комбинации двух групп модулей: Front End, и Back End. При этом первая группа отвечает за то, чтобы вторая группа вовремя снабжалась материалом для обработки. А подсистема Back End – это подсистема исполнительных устройств процессора, в самом широком смысле слова. То есть именно та часть процессора, которая «думает», плюс обслуживающая ее логика. Таким образом, у каждой подсистемы процессора своя задача: Memory Subsystem снабжает процессор данными из памяти, Front End приводит их к удобоваримому виду и снабжает Back End материалом для обработки, а Back End ведает непосредственной обработкой этого материала. Специальная группа устройств отвечает за то, чтобы заранее «подтащить» данные, чтобы как можно точнее угадать направление следующего перехода – то есть выполняет, с одной стороны, сугубо служебную, а с другой, весьма нужную функцию: создание наиболее комфортных условий для работы остальных групп.
Соответственно, будет вполне логичным рассматривать устройства, учитывая именно такое распределение блоков по группам.
Начнем с группы Back End. То есть, с функциональных устройств, и обслуживающей их логики. Взглянув на схему, можно заметить, что функциональных исполнительных устройств пять штук, каждое из них выполняет свой перечень операций. Несколько обособленно стоят блоки вычисления и загрузки адресов. Три устройства из указанных пяти (два fast ALU и одно slow ALU) относятся к блокам операций с фиксированной точкой, два – к блокам операций с плавающей точкой. Все эти блоки связаны с блоками логики, которая подготавливает для них данные, передает операнды, считывает данные из регистров – в общем, выполняет ту работу, без которой произвести вычисления невозможно.
Чтобы проиллюстрировать это утверждение, приведем пример. Что необходимо, чтобы увеличить содержимое некоего регистра «А» на 1? Необходимо проделать следующие действия:
1. Взять содержимое регистра «А»
2. Взять число 1
3. Отправить два числа и код операции («сложение», «увеличить) на исполнительное устройство
4. Произвести сложение
5. Записать результат
Легко заметить, что непосредственно функциональные устройства заняты только одной операцией, четвертой по порядку. Все подготовительные работы (передача данных) делает обслуживающая функциональные устройства логика. Функциональные же блоки в нашем примере принимают числа, принимают код операции («сложить», «вычесть», «изменить знак»), производят саму операцию, и выдают результат, тоже число. Их задача важна, но без обслуживающей их логики они бессильны.
Теперь усложним наш пример. Пусть у нас есть два задания. Задание первое: сложить содержимое регистров «А» и «В». Задание второе: увеличить содержимое регистра «С» на единицу.
Безусловно, можно оба этих задания выполнить по очереди, в порядке, указанном в предыдущем примере. Тогда нам понадобится довольно много времени. Вот если бы у нас было еще одно ничем не занятое исполнительное устройство, то эту работу можно было бы сделать вдвое быстрее. Это пример, когда второе функциональное устройство может вдвое увеличить нашу производительность.
Мы пришли к идее суперскалярного процессора – процессора, способного выполнить более чем одну операцию за такт. Собственно, возможность исполнять более чем одну операцию за такт и составляет суть понятия «суперскалярность». Например, Pentium 4 – суперскалярный процессор. Тем не менее, вполне могло оказаться так, что второе задание предусматривало бы увеличение на единицу регистра «В». Тогда мы были бы вынуждены ждать, когда выполнится первое устройство – несмотря на то, что у нас было бы в наличии второе совершенно свободное функциональное устройство! Соответственно, логика, обслуживающая функциональные устройства, должна определять, есть ли взаимозависимости в заданиях, или же их можно выполнять параллельно. Данная задача также возложена на группу Back End устройств; в частности, ядро Pentium 4 способно исполнять до трех элементарных инструкций каждый такт, поэтому обслуживающая логика обязана очень быстро разобраться с взаимозависимостями этих инструкций.
Как мы уже выяснили, для повышения производительности выгоднее как можно больше работы выполнять параллельно, но это не всегда возможно. Но, может быть, можно запустить не только рядом стоящую микрооперацию, но и более удаленную, которая должна была быть запущена позднее? Пропустив несколько микроопераций с еще не готовыми операндами? Разумеется, выполнять можно только такие инструкции, изменение порядка которых не приведет к изменению результата – это условие тоже придется контролировать.
Вот мы и пришли к основной идее Out-of-Order (внеочередного) исполнения. Представим себе, что у нас есть некоторое количество заданий. Причем выполняться они должны в определенной последовательности, потому что часть из них зависит от результатов предыдущих операций. А часть – не зависит. Третья часть так и вовсе ждет данных из памяти, и еще долго не будет выполняться.
Есть два варианта решения проблемы: либо ждать, пока все задания не будут выполнены «гуськом», согласно первоначальному коду программы, либо попытаться выполнить ту часть работы, для которой уже все необходимое есть. Разумеется, все задания выполнить «без очереди» не удастся, но, если выполнить хотя бы часть их, это сэкономит нам некоторое количество времени.
Давайте подумаем, что принципиально необходимо для решения такой задачи. Нам необходим некоторый буфер, в котором будут накапливаться наши задания. В архитектуре Р6 этот буфер называется reservation station. Из этого буфера некое устройство (забегая вперед, скажем, что это устройство называется планировщиком; детали его функционирования будут рассмотрены в последующих главах) будет выбирать те задания, которые уже снабжены операндами и могут быть выполнены прямо сейчас. Это же устройство должно разбираться с тем, какие задания можно исполнять «без очереди», а какие – нельзя. Поскольку полученные в результате исполнения заданий промежуточные данные необходимо куда-то записывать, нам нужны свободные регистры. Но регистров общего назначения всего восемь. Тогда как заданий в буфере может быть и больше. Не говоря уже о том, что мы не можем просто так распоряжаться теми регистрами, которые уже заняты предыдущими микрооперациями.
Поэтому есть необходимость в наборе служебных регистров. В достаточно большом наборе, чтобы регистры в нем можно было использовать без особых ограничений (в частности, в процессоре Pentium 4 число служебных регистров составляет 128 штук). Ну а поскольку никакая х86 программа не подозревает о существовании более чем 8 регистров общего назначения, надо, чтобы наши служебные регистры умели притворяться этими самыми регистрами общего назначения. Нам нужен блок, который так и называется: блок переименования регистров. По сути, он занят только одним делом: когда какому-нибудь заданию понадобится регистр общего назначения (например, регистр А), надо взять первый попавшийся свободный регистр, обозвать его «А», и позволить заданию, выполнившись, записать туда результат. А когда придет очередь (первоначальная, обусловленная кодом программы), взять результат из этого регистра (освободив его), и отправить дальше, в соответствии с кодом программы.
Ровно также происходит и в процессоре Pentium 4: если некоторая часть заданий может быть выполнена «вне очереди», обслуживающая логика при этом выполняет их как бы «на черновике», запоминая результаты в специально отведенных регистрах. Позднее, когда будут выполнены задержавшие нас операции, логика процессора сохранит данные в строгом соответствии с порядком, указанным в программе. Внеочередное исполнение команд – еще одна важная задача Back End.
Перейдем к Front End – группе устройств, отвечающих за декодирование и хранение инструкций.
Прежде всего, изложим ту проблему, с которой столкнулись производители процессоров. В целях повышения частоты работы мы уже пришли к необходимости сделать каждую стадию конвейера как можно более простой. Но есть очевидная сложность, связанная с нерегулярной структурой и разной степенью сложности х86 инструкций: х86 инструкции имеют разную длину, разное количество операндов, и даже разный синтаксис. Две инструкции одинаковой длины могут означать работу, отличающуюся по трудоемкости на порядки. Дальше есть два варианта выхода: либо делать исполнительные устройства «умными», способными самостоятельно выполнить любую инструкцию, либо сделать так, чтобы на Back End поступали уже гораздо более простые инструкции.
Первый путь означает невысокую итоговую частоту, поскольку каждое функциональное устройство будет самостоятельно разбираться с инструкцией. При этом действительно сложные инструкции встречаются достаточно редко, и такое устройство исполнительных устройств было бы совершенно ненужным расточительством.
Второй путь означает, что нам необходимо некоторое устройство, которое из команд х86, имеющих совершенно различную длину (до 15 байт!) и сложность, сделает простые и понятные инструкции для исполнительных устройств. Полученные инструкции должны иметь регулярную структуру, и должны быть такими, чтобы их можно было исполнить на как можно более простых функциональных устройствах. Регулярная структура в данном случае означает вот что: одинаковая длина инструкций, стандартный вид (расположение операндов, служебных меток), примерно равная сложность исполнения. Если команду х86 нельзя представить в виде одной простой инструкции, ее можно представить в виде некоей последовательности простых инструкций.
Уже довольно давно индустрия выбрала второй путь. Такое устройство в составе процессора есть, и называется оно «декодер». Те инструкции, которые получились в результате «перевода» х86 команд в удобный для процессора формат, получили название «микрооперации», (uop-s).
Идеология «микроопераций» не нова, она встречалась нам еще в процессорах Pentium Pro, Pentium II, и Pentium III. Точно также функциональные устройства процессора Pentium 4 работают не с х86 командами, а с микрооперациями (uop-s). Микрооперации получаются в результате обработки х86 инструкций блоком декодера и являются результатом его работы.
На мгновение отвлечемся: для нас является достаточно привычной так называемая Гарвардская схема работы кэшей: – раздельные кэши данных и инструкций. В частности, по такой схеме работал процессор Pentium III. Но, в отличие от Pentium III, имеющего ставшую практически традиционной схему декодирования команд, в Pentium 4 эта схема заметно модифицирована.
Вместо традиционного, привычного кэша команд, в котором хранится код х86, Intel ввела модифицированный кэш команд: Trace cache. Он расположен после декодера, но перед остальными блоками процессора. В нем хранятся уже не х86 инструкции, а результаты их декодирования, микрооперации. В такой схеме декодер работает независимо от остальных блоков, наполняя Trace cache микрооперациями с темпом, не превышающим одну х86 инструкцию за такт. Если изначально в Trace cache нет инструкций некоторого затребованного процессором участка кода, они будут сравнительно медленно загружаться из кэша L2, декодируясь на ходу. Естественно, что декодирование и выборка данных на этом участке происходят строго в очередности, определяемой исполняемой программой. Микрооперации «снимаются» прямо с декодера, по мере их готовности, и результирующая скорость будет не более одной х86 инструкции за такт.
При втором обращении в Trace cache уже будет найдена соответствующая запись, и уже декодированные микроинструкции выбираются с темпом до шести микроопераций за два такта (Trace cache работает с половинной частотой!). При этом при повторном обращении к тому же участку кода процессор избавляется от необходимости производить декодирование еще раз.
Кстати сказать, экономия в ряде случаев получается весьма значительной: несмотря на крайнюю скрытность Intel в вопросе «сколько тактов происходит декодирование», косвенные данные позволяют предположить, что «длина» участка декодера в тактах составляет от 10 – 15 (минимальная оценка) до 30 (максимальная оценка) тактов! То есть, сравнима со всей остальной частью конвейера Pentium 4! Для средней программы вероятность нахождения запрашиваемого участка кода в Trace cache лежит, как правило, в пределах 75-95%.
В большинстве случаев каждая х86 инструкция превращается в микрооперации количеством от одной до четырех. Так декодируются простые х86 инструкции. Как правило, каждая микрооперация занимает в Trace cache одно место, но в некоторых особых случаях одна позиция Trace cache может содержать две микрооперации. Сложные х86 инструкции превращаются в специальные микрооперации (MROM-векторы), либо в их смесь с обычными микрооперациями. Упомянутые MROM-векторы являются своеобразной «закладкой» для обозначения некоей последовательности микроопераций, и, кроме того, занимают минимальное место в Trace cache. Когда соответствующий участок кода необходимо будет исполнять, MROM-вектор будет направлен в Microcode ROM, который в ответ выдаст обозначенную этим MROM-вектором последовательность нормальных микроопераций. Благодаря такому способу записи микроопераций мы экономим место в Trace cache.
Интересным и весьма часто задаваемым вопросом является объем Trace cache. Сама Intel приводит в качестве его емкости число в 12 000 хранимых микроопераций, но для сравнения с привычным нам объемом кэша инструкций неплохо было бы посчитать эффективный объем Trace cache (в килобайтах кода). Понятно, что в силу особенностей его устройства на разных видах кода эффективные объемы Trace cache будут отличаться. Примерные расчеты дают число от 8КВ до 16КВ кэша «стандартной организации», в зависимости от метода подсчета.
Мы же пока вернемся к Front End группе. Дело в том, что у нас есть еще одна проблема, кроме представления х86 команд в удобной для процессора форме.
Эта проблема – проблема переходов. Вот в чем ее суть. Пусть у нас есть некий кусок программы, который выполняется нашим процессором. Все идет замечательно: декодер превращает х86 команды в микрооперации, исполнительные устройства их исполняют. Благодать. Но если в тексте программы есть инструкция перехода, нам надо узнать это не тогда, когда исполнится предыдущая инструкция, а заметно раньше. Иначе мы, неожиданно узрев инструкцию перехода, будем вынуждены задерживаться тем больше, чем больше длина конвейера – нам ведь надо дождаться, пока произойдет переход.
Чтобы мы не теряли времени, существует специальный блок, блок предсказания переходов (Branch Prediction Unit). Его задача – попытаться предвидеть направление перехода, и, таким образом, сэкономить нам время. В случае удачного предсказания. И, соответственно, ввести процессор в большой штраф (полная остановка конвейера и очистка буферов), если результат «предвиденья» будет неудачным.
Второй случай, когда нам нужен такой блок – если в программе есть условные переходы. То есть такие, которые зависят от результата выполнения какой-либо операции. Поэтому надо постараться «угадать», произойдет этот переход, или нет.
Если гадать просто так, наобум, хорошего выйдет мало. Или вовсе не выйдет. Чтобы блоку предсказаний было немного легче, он хранит специальную таблицу историю переходов (Branch History Table), в которой записана результативность предыдущих примерно 4 000 предсказаний.
Кроме того, отслеживается точность только что произошедшего предсказания, чтобы при необходимости откорректировать алгоритм предсказаний. Благодаря этому декодер, де-факто, выполняет по подсказке блока BPU условный переход, а затем BPU проверяет, правильно ли было предсказано это условие.
Таким образом, мы незаметно перешли к таким устройствам, как Branch Prediction Unit, и механизм предзагрузки (предвыборки) prefetch. Задача последнего – «угадать», какие данные понадобятся процессору в дальнейшем. Естественно, «угадывает» он не на пустом месте: специальные механизмы анализируют последовательности адресов, по которым происходила загрузка данных, и пытаются предугадать следующий адрес.
Необходимость в нем возникла вот почему. В процессе исполнения программы наступает момент, когда надо обратиться к памяти, и запросить оттуда данные. Все бы ничего, но процесс получения данных из памяти катастрофически долог – сотни процессорных тактов. В течении которых процессору будет попросту нечего делать. Поэтому, если данные мы запросим заранее, то сэкономим много времени, и увеличим эффективность работы всего остального процессора. Вся сложность в том, чтобы понять, куда надо бежать за данными, и какие данные нам понадобятся в следующий раз. Впрочем, к некоторым деталям функционирования механизма предзагрузки мы еще вернемся, на этом этапе вполне достаточно знать о его существовании. Работает механизм предвыборки в тесном содружестве с Branch Prediction Unit, и с третьей группой устройств, Memory subsystem.
Осталась у нас подсистема памяти. Тем более, что ее задача сравнительно проста: как можно быстрее доставить затребованные данные, и как можно быстрее убрать полученный результат. Ну а поскольку частоты работы современной памяти не идет ни в какое сравнение с частотами работы процессора, то активно используются кэши различных уровней: небольшие объемы высокоскоростной памяти для хранения наиболее часто требуемых данных. Процессор Pentium 4 имеет два, некоторые разновидности имеют три уровня кэшей.
Основная роль в процессоре Pentium 4 принадлежит кэшу второго уровня. Фактически, именно кэш второго уровня становится основным хранилищем данных в микроархитектуре Pentium 4. Причина такой организации станет ясна далее.
В процессе работы наиболее необходимые данные, как и прежде, размещаются в кэше первого уровня. Но, в отличие от предыдущего поколения процессоров, Pentium III, размер этого кэша данных весьма невелик: всего 8КВ у ядер Willamette/Northwood (16КВ у ядра Prescott). Зато весьма велика скорость этого кэша: задержка доступа составляет всего 2 такта, в отличие от 3 тактов в Pentium III. Разница кажется не слишком большой, но если припомнить характерные частоты работы (для одинаковых технологических процессов это 1GHz для Pentium III и 2GHz для Willamette), то окажется, то вместо трех наносекунд кэш данных первого уровня теперь управляется за одну наносекунду! Вот эта разница выглядит уже гораздо более впечатляющей.
Поскольку, как уже говорилось, объем кэша данных первого уровня невелик, есть немалая вероятность, что необходимых нам данных там не окажется. Ведь, фактически, 8КВ (16КВ) – это меньше «области локальности» большинства программ (кроме специальным образом написанных). В случае отсутствия необходимых данных инициируется обращение в кэш второго уровня. От предшественника Pentium 4 унаследовал неблокирующийся кэш второго уровня, умеющий обрабатывать до 8 запросов. Если нужные нам данные есть – получаем их, копируя данные в кэш первого уровня по шине шириной 256 бит! При этом Pentium 4 может копировать 256 бит данных каждый такт! Эта технология получила название Advanced Transfer Cache и является развитием соответствующей технологии процессора Pentium III, каковой умел копировать 256 бит каждый второй такт. Подобная полоса пропускания шины нужна, например, потому, что при обращении к разным строкам кэша процессор не может начинать работу со второй строкой, не закончив передачу первой. Поэтому столь большая – с точки зрения теории, так и вовсе избыточная – скорость передачи данных в реальной жизни все же вполне востребована.
Если необходимых нам данных в кэше второго уровня нет, модуль управления шиной (Bus Unit) задействует оперативную память, направляя в нее соответствующий запрос. Вполне понятно, что время реакции оперативной памяти намного больше, нежели время реакции кэша второго уровня (для ядра Northwood указана задержка в 7 тактов; в ядре Prescott ситуация изменилась, задержка составляет 18 тактов). Естественно, что, с точки зрения процессора, запрос в оперативную память – это ЧП (чрезвычайное происшествие), поскольку характерное время ответа памяти исчисляется сотнями процессорных тактов. Именно поэтому так необходим механизм предзагрузки – он должен был угадать, какие данные нам понадобятся, чтобы заблаговременно начать их доставку.
Но вернемся к кэшу. Размер кэша второго уровня составляет 256КВ для ядра Willamette, 512КВ для ядра Northwood, и 1МВ для ядра Prescott. Кроме того, процессор Pentium 4 XE содержит кэш третьего уровня объемом 2МВ (в процессорах Xeon размер кэша третьего уровня может доходить до 4МВ). Этот кэш подключен к ядру шиной шириной 64 бита, имеет более высокую латентность, нежели кэш второго уровня, и является инклюзивным – то есть, содержимое кэша второго уровня дублируется в нем, занимая часть объема. Тем не менее, во многих программах эффект от его наличия вполне заметен: уступая по скорости всем предыдущим иерархиям кэшей, кэш третьего уровня все равно заметно превосходит по скорости оперативную память.
Вот вкратце основные модули процессора, поделенные на функциональные блоки. Безусловно, данное описание не является полным, это лишь иллюстрация схемы работы процессора. Более подробно функционирование отдельных подсистем будет рассмотрено в последующих главах.
Далее: Prescott: Последний из могикан? (Pentium 4: от Willamette до Prescott). Часть 2



© 1998-2023 fcenter.ru | Россия
© 1998-2023 fcenter.ru | Россия