Ваш город: Москва
Prescott: Последний из могикан? (Pentium 4: от Willamette до Prescott). Часть 2
Глава четвертая, в которой мы убедились в справедливости равенства 2 х 2 = 4 и сделали правильные выводы
Данную главу мы посвятим такой особенности микроархитектуры NetBurst, как блоки ALU; в том числе блоки ALU удвоенной частоты.
Припомним, что основная задача микроархитектуры Pentium 4 состоит в повышении производительности путем увеличения частоты. Для повышения частоты важно как можно быстрее исполнять основные целочисленные операции. Но блоки целочисленных операций существенно отличаются по сложности, поскольку отличаются по сложности исполняемые ими операции: часть из них более сложна, часть менее.
Впрочем, инженеры Intel нашли своеобразный, но эффективный способ увеличить темп обработки операций с целыми числами. Все микрооперации, которые идут на ALU, могут быть исполнены двумя видами устройств: одним [целочисленным] устройством slow ALU, и двумя [целочисленными] устройствами fast ALU. Первое устройство представляет собой ALU, которое может обработать сравнительно большое число целочисленных операций; в частности, на нем исполняются наиболее сложные целочисленные операции. По крайней мере, так мы изначально думали, исходя из его названия – действительность, похоже, оказывается несколько более изощренной. Впрочем, вернемся к теме.
Два устройства fast ALU интереснее и заметно более специализированны. Они предназначены для обработки простых целочисленных операций – например, сложение двух целых чисел. Но зато это самое сложение они делают гораздо быстрее, чем slow ALU, поскольку работают на удвоенной частоте процессора. То есть, процессор частотой 3GHz содержит некоторое количество устройств, которые работают на частоте 6GHz (отметим, что fast ALU не единственные блоки, работающие на удвоенной частоте, они лишь часть более обширной системы)! Отметим, что эти два устройства не идентичны друг другу: fast ALU 0 более универсальное, нежели fast ALU 1, и умеет исполнять большее количество команд.
Но самое главное: оказывается, для того, чтобы легче было увеличить частоту на этом участке процессора, fast ALU состоит из двух "подустройств" шириной 16 бит(!), сдвинутых друг относительно друга на одну стадию. Операция сложения чисел разбита на несколько стадий, чтобы уменьшить количество работы на каждой стадии – все это ради того, чтобы увеличить частоту работы fast ALU. Оговоримся, что пока мы будем говорить о ядре Northwood, ядро Prescott заметно от него отличается.
В результате fast ALU обрабатывает числа по "половинкам". Зато делает это не каждый такт, а вдвое быстрее, по полутактам (они именуются "тиками", tick). Точнее сказать, оно работает на собственной частоте, которая вдвое больше частоты остального процессора (назовем ее "номинальной частотой"). Напомним, что, говоря о частоте остального процессора, мы исключаем Trace cache (работающий на вдвое более низкой частоте, чем кэш данных) и еще несколько блоков, работающих на той же удвоенной частоте, что и fast ALU. Каждый процесс в fast ALU синхронизируется по половине номинального такта процессора. Соответственно, каждый такт fast ALU по длительности точно равен половине "номинального" такта. Все блоки, работающие на удвоенной частоте, получили название Rapid Execution Engine, хотя сейчас наметилась тенденция использовать этот термин в более широком понимании. Резюмируем: в процессоре Pentium 4 в одно и то же время ряд блоков работает на различных частотах: Trace cache на половине номинальной частоты, Rapid Execution Engine (куда входят fast ALU и обслуживающие их блоки) на удвоенной номинальной частоте, а остальные блоки процессора – на номинальной.
Процесс сложения двух чисел происходит так: на первом тике (полтакта) fast ALU складывает 16 младших разрядов двух складываемых 32-х битных чисел. Процесс очень похож на складывание в "столбик" двух чисел. Два коротких числа легко можно сложить в уме. Два длинных приходится записывать, и складывать в них цифры поочередно. Точно таким же образом два коротких числа ALU способно сложить очень быстро. Но два длинных складываются заметно дольше. Поэтому, чтобы можно было увеличить скорость сложения чисел (для увеличения темпа их обработки), 32-х битные числа складываются поочередно, по 16-ти битным половинкам числа. Часто бывает, что у нас появляется число следующего разряда. При сложении в "столбик" мы это число просто запоминаем. В процессоре это число имеет название "бит переноса". К концу первого тика вычисляется бит переноса для младших разрядов двух чисел.
На втором тике второе 16-ти разрядное "подустройство" fast ALU, "сдвинутое" на полтакта относительно первого, занимается сложением старших 16-ти разрядов первой пары чисел, также с участием соответствующего бита переноса.
На третьем тике станут известны служебные флаги, которые сопровождают операции над числами (было ли переполнение, нулевой ли результат, получено ли отрицательное значение и так далее). Эти флаги могут быть использованы для дальнейших операций: например, для условных переходов.
Обратим внимание, что на втором тике первое "подустройство" fast ALU, обрабатывающее младшие 16 разрядов, уже закончило работу. Естественно, вполне логично было бы его чем-нибудь занять. Так и происходит: на втором тике первое "подустройство" fast ALU обрабатывает уже следующую пару чисел! В результате у нас запущено сложение второй пары чисел с промежутком всего полтакта!
Чего же, в результате, мы добились? Прежде всего, мы сильно выиграли в темпе запуска новых сложений по сравнению с ALU традиционной структуры. В самом деле, вместо одной пары чисел за такт мы теперь можем запускать новую пару каждых полтакта! Что дает нам две пары чисел за такт.
На первый взгляд, расплачиваться за увеличившийся темп пришлось увеличившимися задержками, полтора такта вместо одного в ALU традиционной структуры. Правда, слишком сильно расстраиваться не стоит, у нас есть одна замечательная возможность. Взглянем, через какое время будут готовы различные "части" результата:
Младшие 16 разрядов числа будут готовы спустя один тик (спустя полтакта)
Если нам необходимы старшие разряды числа, они будут готовы через 2 тика (один такт).
Если же нам необходимы флаги, то они будут получены спустя 3 тика, или полтора такта.
Возможность, о которой мы говорим – это возможность немедленно передать только что вычисленную половинку результата в качестве частичного операнда для следующей операции сложения. Без потери дополнительного времени на пересылку. Пусть, например, у нас есть цепочка зависимых инструкций сложения. Результаты каждой последующей инструкции зависят от предыдущих результатов. Начинаем обрабатывать первую инструкцию. За первый тик обработана младшая половина результата, и она немедленно передается для выполнения следующей инструкции. На втором тике вычисляется старшая половина результата, и одновременно с этим вычисляется младшая половина следующего результата! И так далее, по цепочке. То есть, цепочка из 100 зависимых операций ADD, каждая из которых имеет операндом результат предыдущей, будет исполняться примерно 50 тактов! В результате, эффективная латентность каждой операции составляет 0.5 такта! Великолепный результат. Именно так работает процессор Pentium 4 на ядрах Willamette и Northwood.
Разумеется, чудес не бывает, поэтому время получения флагов не изменится. Но есть более существенное ограничение: на fast ALU обрабатываются далеко не все операции, а только самые простые, вроде сложения. Для того чтобы указанный выше механизм работал, fast ALU должны исполнять только такие микрооперации, которые обрабатывают операнды строго в направлении от младших разрядов к старшим, но не наоборот. Все неудовлетворяющие этому условию операции будут исполняться на slow ALU. Если при этом нам придется пересылать операнды на Slow устройство, то результирующая задержка составит четыре тика (два такта).
Примером операций, которые могут нарушать удобный нам порядок обработки, являются операции сдвига (shift). Операции сдвига выполняются в ядре Northwood предположительно в блоке FPU. Если еще точнее, то на устройстве под названием MMX-shifter.
Перечитаем внимательно: все сдвиги исполняются на MMX-shifter-е с задержкой 4 такта. Но направляются-то они в slow ALU?! Как это понять? Какая связь между slow ALU и MMX-shifter-ом?
Складывается впечатление, что устройство slow ALU, в некоторой степени, виртуальное устройство! Похоже, это устройство принимает задания, превращает в необходимый формат и направляет туда, где они могут быть исполненными. То есть, служит скорее "помощником и организатором", чем непосредственным исполнителем операций.
Поскольку разные операции исполняются на разных блоках, это приводит к интересным следствиям. Рассмотрим, например, операцию shift "сдвига влево на 4 позиции", то есть умножение на 16. Эту операцию можно выполнить умножением, но это сравнительно долго, поскольку блока целочисленного умножения в Northwood-е нет (!) (в свое время это привело в священный гнев многих "гуру процессоростроения"). Можно выполнить напрямую, и мы уже знаем, что время исполнения такой операции составит 4 такта (то есть 8 тиков). Но, раз уж не все операции равнозначны по времени исполнения, нам выгоднее заменить одни операции другими. В частности, из приведенного выше примера видно, что выгоднее заменять операцию shift, занимающую 4 такта, четырьмя операциями ADD, поскольку суммарное время исполнения последних составит только 2 такта (4 тика)! Более того, вплоть до сдвигов на 7 включительно позиций выгоднее заменять все такие операции shift на операции ADD. Собственно, до появления ядра Prescott компилятор от Intel именно так и делал в генерируемом им коде.
Описанное выше устройство ALU приводит к тому, что отныне для процессора становится очень важным, как именно написана программа. В этом месте микроархитектура Pentium 4 несколько отходит от привычного направления развития микропроцессоров: их уже довольно долго стараются разрабатывать так, чтобы явных перекосов в скорости исполнения различных инструкций не было.
Приведенный пример хорошо иллюстрирует, почему процессор Pentium 4 оказался столь чувствителен к оптимизации программного обеспечения. Впрочем, Intel побеспокоилась о соответствующем компиляторе, поскольку без оптимизации программного обеспечения Pentium 4 не сможет продемонстрировать хорошую производительность.
Теперь самое время сказать несколько слов о Prescott. Мы уже говорили о значительных отличиях его микроархитектуры от микроархитектуры Northwood. Например, в ядре Prescott блоки fast ALU имеют реализацию, отличную от реализации остальных блоков процессора, поскольку ради повышения рабочих частот здесь используется транзисторная логика, основанная на дифференциальных парах! Заметим, что "дифференциальная логика" может работать на заметно более высоких частотах, именно поэтому ее и применили в этих блоках. Но такая логика выделяет заметно больше тепла в пересчете на один транзистор, содержит ощутимо больше транзисторов и, к тому же, выделяет тепло даже на "холостых" циклах.
Заметно это отличие и в части исполнения операций.
Во-первых, эффективная задержка операций, направляемых на fast ALU (в том числе ADD), изменилась. Если ранее она составляла полтакта, то теперь она увеличилась вдвое и составляет один такт. То есть, теперь результат вычислений младших разрядов числа может быть передан на исполнение только спустя один такт. Это означает, что упомянутая ранее цепочка из 100 штук зависимых операций ADD на Prescott-е будет вычисляться примерно 100 тактов, а не 50, как в Northwood-е!
Во-вторых, операции shift теперь относятся к fast ALU. В Prescott-е появился специальный блок, который исполняет те операции сдвига, которые не могут быть выполнены в fast ALU предыдущей конструкции (то есть такие сдвиги, в которых направление не соответствует направлению от младших битов к старшим). Время исполнения таких сдвигов составляет один такт, а темп исполнения – до двух за такт. Ранее, напомним, было 4 такта на исполнение, и темп не выше одного сдвига за такт, поскольку исполнялись сдвиги в MMX-shifter-е.
В-третьих, появился блок целочисленного умножения; мы уже писали, что при обсуждениях процессора отсутствие этого блока частенько доводило "гуру процессоростроения" до эстетических обмороков.
Как мы уже писали, изменились задержки для значительного числа инструкций (более подробно в Приложении 1).
Это приводит к достаточно забавным следствиям: в частности, если раньше для повышения производительности было выгоднее код, содержащий shift, заменять на код, содержащий ADD, то в данном случае ситуация изменилась с точностью до наоборот. В приведенном нами ранее примере такая замена позволяла выполнять заданную операцию не за 4 такта, а за два. Но теперь оптимизированный под ядро Northwood код приведет к тому, что Prescott будет выполнять его 4 (!) такта, то есть дольше, чем НЕ оптимизированный код, который исполнялся бы один такт! Что интересно, Prescott в части времен исполнения инструкций стал гораздо больше похож на остальные х86 процессоры, чем Northwood: времена исполнения операций стали гораздо ближе друг к другу, практически нет таких разбросов, как были в Northwood-е.
Поэтому программное обеспечение, перекомпилированное для использования с ядром Northwood, для ядра Prescott имеет смысл перекомпилировать заново.
Таким образом, в этой главе мы выяснили несколько интересных вещей: наличие в процессоре блоков, работающих на удвоенной частоте (как мы уже говорили, это не только fast ALU, но и некоторые другие блоки); некоторую "виртуальность" устройства slow ALU; существенную разницу между ядрами Northwood и Prescott. Из сказанного выше очевидно, что ALU процессора Pentium 4 отличаются от ALU других процессоров своим достаточно необычным устройством. Это показалось нам достаточно интересным.
Небезынтересен вопрос, связанный с реализацией в ядре Prescott технологии ЕМ64Т (в данный момент эта технология включена только в серверной модификации ядра под названием Nocona). Первое, что приходит в голову: устройство fast ALU для обработки 64-х битных данных вполне может быть организовано аналогично устройству fast ALU в Northwood-е, то есть два "подустройства" шириной 32 бит, сдвинутых друг относительно друга. Именно такая версия пока наилучшим образом объясняет наблюдаемые нами результаты.
Глава пятая, напоминающая нам, что "повторение – мать учения!"
Безусловно, читатель наверняка заметил, что мы как-то слишком уж быстро перескочили непосредственно к исполнительным устройствам, пропустив по дороге весьма значительное количество устройств. Это связано вовсе не с тем, что нам нечего сказать по поводу предыдущих стадий – совсем наоборот, именно там нам удалось найти достаточно интересные подробности. Просто перед тем, как перейти к подробному рассмотрению работы планировщиков и очередей микроинструкций, необходимо вкратце припомнить известные нам данные. Такие, как задержки доступа в кэши разного уровня.
Доступ в кэши различной иерархии характеризуется временем доступа к ним и полосой пропускания шин между ними. Поэтому мы решили собрать данные в таблицы.
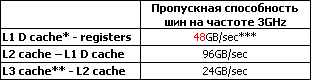
* – данные приведены только для кэша данных, поскольку Trace cache не имеет осмысленной величины полосы пропускания в байтах. Известен максимальный темп, равный 6 uop-ам за 2 такта, но, в силу неизвестного точного размера uop-а, оценить пропускную способность сложно.
** – кэш третьего уровня на сегодняшний момент есть только у ядра Gallatin, представляющего собой разновидность 130нм Northwood-а с интегрированным на кристалл кэшем третьего уровня (с поддержкой ЕСС). На базе этого ядра продаются процессоры под маркетинговыми названиями Pentium 4 Extreme Edition, Xeon MP, Xeon DP with L3 cache.
*** – вообще говоря, более точные значения для пропускной способности шин равны 44.8GB/sec, 89.5GB/sec, и 22.4GB/sec.
Легко заметить, что различные уровни кэша имеют разные особенности. В частности, скорость считывания данных из кэша первого уровня в регистры заметно меньше, чем скорость передачи данных по шине между кэшем второго и первого уровней! Казалось бы, почему так получилось? Зачем он тогда вообще нужен, кэш первого уровня? Какой в нем смысл?
Сделано это потому, что кэш первого уровня имеет задачу, отличную от задачи кэша второго уровня: он должен быстро, с минимальной задержкой найти и выдать необходимые данные. При этом скорость считывания из него не превышает 16Byte/такт (48GB/sec). Кроме того, одна из основных причин необходимости кэша первого уровня состоит в том, что напрямую процессор в кэш второго уровня залезать не может. Чтобы данными можно было воспользоваться, необходимо создать запрос, найти данные, переслать их в кэш данных первого уровня и так далее.
Но если в кэше первого уровня нужных нам данных не найдется, их туда необходимо доставить как можно быстрее.
Для чего это необходимо, можно проиллюстрировать на таком примере. Представим себе, что программе понадобились данные не подряд, по последовательным адресам, а отстоящие друг от друга на расстояние, превышающее длину строки. Либо, что еще хуже, они случайным образом разбросаны по области памяти достаточно большого размера. В этом случае, чтобы прочитать один (!) байт, мы вынуждены переносить всю строку размером 64 байта. То есть, в данном случае количество информации, передаваемой из L2, превышает реально требуемое в 64 раза! Отсюда понятно, чем выше скорость передачи данных из L2 в L1D, тем лучше. Кроме того, непосредственно из L2 cache получает код еще и декодер.
Именно поэтому шина между кэшами имеет фантастически высокую пиковую пропускную способность, 96GB/sec (для частоты 3GHz). Все это сделано для того, чтобы передача данных (и вызванная этим заминка) продолжалась как можно меньше времени. То есть, если несколько утрированно расставить приоритеты, то в ядре Northwood кэш данных первого уровня ориентирован на минимальную латентность, а кэш второго уровня на максимальную скорость передачи данных.
В ядре Prescott специализация уже менее выражена, кэш первого уровня имеет большее время доступа в наносекундах, чем кэш у ядра Northwood. А наблюдаемая пропускная способность шины L1 – L2 у ядра Prescott часто оказывается меньше, чем у ядра Northwood. Это можно продемонстрировать, обращаясь по циклу к началам новых строчек, отсутствующих в L1, но находящихся в L2.
Ядро Northwood стабильно показывает среднюю скорость переноса в районе 32-х байт за такт, а вот в ядре Prescott результат измерения получается ощутимо меньше, примерно в полтора – два раза.
Необходимо уточнить, что в случае кэша первого уровня скорость выдачи информации сильно зависит от того, что именно мы измеряем. В случае, когда ядро считывает данные из кэша L1D (кэш данных первого уровня), максимальная скорость считывания составляет 48GB/sec. Но если мы ведем передачу данных из кэша L2, они приходят в L1D со скоростью 96GB/sec.
Отсюда понятно, что физический смысл двух цифр пропускной способности разный: поскольку данные никуда не могут "потеряться", приходится сделать вывод, что в разных ситуациях кэш L1D работает с разной скоростью. Именно поэтому давать одну цифру бессмысленно, надо оговаривать, какую ситуацию мы имеем в виду. Более того, скорость выдачи данных зависит еще и от того, какие данные мы затребовали! Например, для передачи из L1D в SSE2 регистры скорость не превышает 16 байт за такт. Для передачи из L1D в MMX регистры скорость не превышает 8 байт за такт. Ну а для передачи из L1D в целочисленные регистры – не более 4-х байт за такт. Вот так вот все непросто.
Отметим, что одновременно с чтением может идти и сохранение данных. Но при этом максимальный темп в 16Byte/такт недостижим, поэтому наша оценка в 48GB/sec как максимальной скорости выдачи данных остается справедливой.

* - в случае, если доступ идет к открытой странице. В связи с относительно небольшими размерами TLB доступ в L3 cache почти всегда идет к закрытой странице. В таком случае задержка составляет примерно 50 тактов.
Длина строки кэша L1D составляет 64 байта. Каждый такт из кэша второго уровня может быть подгружено 32 байта данных, то есть половина строки кэша.
Кэш второго уровня организован линиями по 128 байт, которые разделены на два сектора по 64 байта; каждый из секторов может считываться независимо. Причина такой организации становится понятной, если вспомнить, что из памяти данные передаются блоками именно по 128 байт, а вот в память блоками по 64 байта.
Кэш третьего уровня для нас не слишком интересен, поскольку в микроархитектуре NetBurst имеет вспомогательное значение. Представляет собой кэш размером до 4МВ, расположенный на кристалле процессора, и соединенный с ядром шиной шириной 64 бита. Время доступа к нему выше, чем к кэшу второго уровня, но зато намного меньше, чем к памяти. К тому же его размер заметно больше, чем у кэша второго уровня, что благотворно сказывается на вероятности нахождения данных в нем.
Кэши второго и третьего уровней не блокирующиеся, способны обрабатывать до 8-ми запросов одновременно. У ядра Northwood кэш первого уровня 4-х канальный частично-ассоциативный, у ядра Prescott 8-ми канальный частично-ассоциативный.
Важный нюанс: приведенные в документации цифры латентности доступа в кэши отличаются от тех, которые получаются на практике, поскольку не учитывают стратегии работы кэша. Эти цифры представляют собой задержки кэша второго уровня, если бы он был изолирован от всех остальных подсистем.
Но любое реальное обращение в кэш второго уровня для ядра Northwood покажет цифру 9 или более тактов. При необходимости получить новые данные, они всегда ищутся прежде всего в кэше первого уровня. Если необходимых данных там нет, то поиск продолжается в следующих иерархиях кэшей. В данном случае это будет обозначать следующее: суммарная задержка составит 2 такта в кэш первого уровня плюс 7 тактов в кэш второго уровня.
Соответственно, реальная задержка в ядре Prescott будет 22 такта, либо более. Отметим, что получить данные цифры будет совсем не просто, приходится составлять запросы специальным образом, чтобы исключить влияние prefetch-а.
Кстати, о prefetch-е. Этот механизм (напомним, его суть в том, чтобы вовремя "подтаскивать" ядру процессора нужные данные) получил в Prescott-е некоторое развитие. Точнее, были сняты те ограничения, которые присутствовали в ядре Northwood. В частности, в ядре Northwood использовался prefetch, который не мог пересекать границу 4КВ страницы виртуальной памяти, что сильно снижало его эффективность. Суть проблемы в том, что prefetch в Northwood может загрузить данные страницы только тогда, когда ее запись уже находится в TLB. Если при обращении к данным следующей "по курсу" страницы её записи нет в TLB, то ядро Northwood не инициирует обращение к таблицам страниц с целью трансляции и не добавляет запись в TLB. Именно поэтому prefetch в Northwood "не пересекает" границу 4КВ. То есть, он может "пересечь" эту границу, если запись о странице находится в TLB. Но не может добавить запись о странице в TLB, если её там нет.
В Prescott-е все изменилось: теперь prefetch более агрессивен и уже не имеет таких ограничений, как 4КВ граница страницы виртуальной памяти. Кроме того, он заметно лучше обрабатывает выходы из циклов.
В результате этих усовершенствований (а также улучшения работы с шиной) сильной стороной ядра Prescott стала работа с памятью. А вот работа с кэшем (точнее, ее эффективность) несколько снизилась, максимально достижимая пропускная способность уменьшилась, особенно в случае записи. Впрочем, выше мы это уже писали.
Надо отметить, что с изменением объемов кэшей первого и второго уровня изменилась и скорость обработки всевозможных конфликтов кэша, среди которых одна из ведущих ролей принадлежит конфликтам алиасинга. В данном случае этот термин обозначает ситуацию, когда два различных адреса в памяти имеют, например, идентичные младшие 16 бит. Тогда при попытке размещения обеих строчек памяти в кэше и поочередном к ним обращении они будут постоянно вытеснять друг друга из кэша, что резко снижает эффективность кэширования.
Поскольку тема алиасинга нами не освещалась, приведем более подробное описание.
Проблема алиасинга
Для того, чтобы разобраться с проблемой алиасинга, нам придется припомнить, как устроен n-канальный частично-ассоциативный кэш.
Легче всего представить себе кэш в виде некоего трехмерного куба, который изображен на рисунке. Количество "слоев" (линий кэша) в одном наборе set равно количеству банков (каналов), way. Вертикальный срез представляет собой набор set, содержащий строки кэша, совпадающие по индексам. Перевод несколько некорректный, но так уж исторически сложилось.
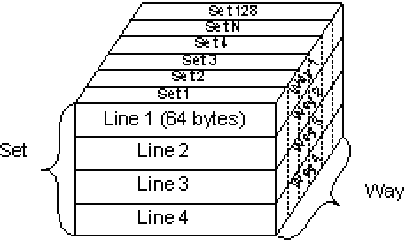
Рассмотрим какой-нибудь реально существующий кэш. Пусть, например, это будет кэш L1D процессора Northwood общим объемом 8КВ. Известно, что кэш первого уровня у ядра Northwood представляет собой 4-х канальный частично ассоциативный кэш, содержащий в каждой строке по 64 байта данных.
Он представляет собой набор из 4-х слоев (way), каждый из которых состоит из 32-х строк (set 1, set 2, set 3…). На нашем рисунке каждый слой (канал кэша) обозначен надписями Line 1, Line 2, и так далее. Размер каждой строки 64 байта. Суммарный объем равен 4 * 32 * 64 = 8 192 байта, или же 8КВ.
Когда нам необходимо разыскать некоторый адрес, происходит следующая операция: логика контроллера кэша параллельно обрабатывает в каждом из наборов младшие биты адреса, находя набор set, имеющий необходимые нам биты с шестого по десятый. Затем при помощи битов 11:15 внутри найденного набора (set) идентифицируется и отбирается та строка (way), тэг которой соответствует нашему запросу. В результате получаем необходимый нам элемент.
Вот в этом самом месте нас и поджидает первая "засада". Поскольку обработать все биты адреса быстро не получится, мы обрабатываем только часть из них. Но два разных адреса, имеющих при этом идентичные младшие 16 бит адреса, совершенно одинаковы с точки зрения логики контроллера кэша. В результате, обращаясь поочередно по двум адресам, имеющим идентичные 16 бит, получим ситуацию, когда они попеременно будут вытеснять друг друга из кэша.
Эта проблема получила название проблемы алиасинга.
В ядре
Prescott эта проблема была решена более разумно. Теперь set по-прежнему идентифицируется по битам 6:10, но идентификация way изменена, она происходит по битам 11:21. То есть, по одиннадцати битам, а не по пяти. Результат: теперь проблема алиасинга встречается для адресов, отстоящих не на 64КВ, как у Northwood, а через 4МВ.
Кроме того, несколько изменилась степень ассоциативности кэша первого уровня, теперь это 8-ми канальный частично-ассоциативный кэш первого уровня. Наборов set по-прежнему 32, каждая строка содержит 64 байта. Объем равен 8 * 32 * 64 = 16 384 байта, или 16КВ.
Результат: скорость доступа в кэш несколько упала (теперь задержки составляют 4 такта вместо 2-ух), но зато проблема алиасинга практически исчезла. Соответственно, намного более редкими стали связанные с алиасингом штрафы. Точнее, штрафы алиасинга стали несколько больше, но возникать они стали намного реже.
Разумным будет предположить, что увеличенная длина тэгов – одна из основных причин увеличения задержки доступа в кэш первого уровня.
Необходимо также упомянуть, что, кроме 64КВ алиасинга, у ядра Northwood есть еще один алиасинг, на уровне 1МВ. Природа его не столь ясна; наиболее правдоподобное предположение состоит в том, что проверка битов 20:31 отложена до того момента, когда данные прибудут из кэша. В большинстве случаев это позволяет ускорить обработку, но иногда из-за отложенной проверки возникают коллизии.
Проблема алиасинга отнюдь не всегда обязана присутствовать в кэше первого уровня. В частности, в процессорах на ядрах К7/К8 этой проблемы нет, поскольку всегда проверяются все биты адреса.
Наступило время внимательно посмотреть на конвейер процессора Pentium 4, и постараться упорядочить все, что нам известно о конвейере.
Далее: Prescott: Последний из могикан? (Pentium 4: от Willamette до Prescott). Часть 3



© 1998-2023 fcenter.ru | Россия
© 1998-2023 fcenter.ru | Россия