Ваш город: Москва
Первое знакомство с микроархитектурой Intel Nehalem
Введение
О том, что в 2008 году нас ждёт встреча с процессорами Intel с новой микроархитектурой, известно очень давно. Это стало ясно ещё два года назад, когда компанией была представлена концепция развития «Tick-Tock», согласно которой каждый год меняется либо технология производства процессоров, либо их микроархитектура. В прошлом году Intel представила процессоры семейства Penryn, представляющие собой обновлённые Core, выпуск которых был переведён на 45-нм технологический процесс с использованием соединений гафния. Следовательно, в этом году пришла очередь новой микроархитектуры – Nehalem, первыми представителями которой выступают процессоры Bloomfield, ориентированные на использование в настольных системах.

Чередование внедрения новых технологических процессов и разработки новых микроархитектур позволило компании Intel избавиться от задержек при анонсе новых процессоров. Поэтому ровно через год после представления семейства Penryn мы вновь поднимаем тему процессорных нововведений: неминуемо приближается дата появления на рынке процессоров с микроархитектурой Nehalem.
Учитывая значительность этого события, мы решили разделить наш первый материал, посвящённый ожидаемой новинке, на несколько частей. Сегодня мы поговорим об особенностях архитектурных и технологических решений, нашедших место в перспективных процессорах, а затем выйдет вторая часть статьи, в которой нас будет ждать подробное знакомство с производительностью Nehalem в реальных задачах и другими не менее важными его потребительскими качествами.
Общие принципы микроархитектуры Nehalem
Прежде чем начать знакомство с многообещающей микроархитектурой Nehalem, несколько слов необходимо сказать о причинах её появления. Ведь хотя её создание ведётся очень давно, вряд ли компания Intel заинтересована в скорейшем появлении процессоров на ней основанных только лишь ради вписывания в самой же сформулированный план «Tick-Tock». Очевидно, что на первый взгляд весьма успешная микроархитектура Core чем-то не удовлетворяет микропроцессорного гиганта, причём причины этого не лежат на поверхности. Процессоры Core полны преимуществ, хорошо продаются и на голову переигрывают предложения конкурента.
Оказывается, существенным недостатком Core, особенно досаждающим Intel, стал их немодульный дизайн. Выступая дальнейшим развитием мобильных процессоров Pentium M, микропроцессоры Core 2 изначально проектировались как двухъядерные полупроводниковые кристаллы. Последующий же переход к выпуску многоядерных представителей семейства Core 2 стал выявлять слабые места такого подхода. Так, четырёхъядерные и недавно вышедшие шестиядерные представители микроархитектуры Core просто собирались из нескольких двухъядерных кристаллов, что приводило к затруднению взаимодействия между ними. Обмен данными между разрозненными ядрами организовывался через системную память, что порой вызывало большие задержки, обусловленные ограниченной пропускной способностью процессорной шины.
Ещё одно узкое место возникало в многопроцессорных системах. Хотя Intel уже решил проблему с разделением системной шины, выпустив чипсеты, предлагающие собственную шину каждому процессору, производительность часто ограничивалась недостаточно высокой пропускной способностью шины памяти. Эту проблему, например, можно было наблюдать даже в ориентированной на энтузиастов платформе Skulltrail, не говоря уже о высокопроизводительных рабочих станциях и серверах.
Иными словами, дальнейшее увеличение многоядерности и многопроцессорности, выбранное основным вектором увеличения производительности современных систем, рано или поздно должны были завести Intel в тупик, даже несмотря на то, что сама по себе современная микроархитектура Core и представляется очень удачной. Именно поэтому Intel и стремится к скорейшему переходу на Nehalem – микроархитектуру, которая в первую очередь решает описанные структурные проблемы. Ведь ключевыми особенностями Nehalem, бросающимся на вид при первом знакомстве, стали интегрированный в процессор контроллер памяти и новая шина с топологией точка-точка Quick Path Interconnects (QPI), позволяющая не только связывать процессор с чипсетом, но и несколько процессоров между собой напрямик.
Все эти нововведения перекликаются со строением процессоров AMD, и это действительно так: о перспективности встраивания контроллера памяти в процессор и связывания процессоров между собой в многопроцессорных системах AMD догадалась несколько лет назад. Однако в роли догоняющего Intel выступает только в плане архитектурных улучшений: по удельной производительности процессоров она лидирует с момента выхода микроархитектуры Core.
Вторым важным нововведением в Nehalem стал модульный дизайн процессора. Фактически, микроархитектура сама по себе включает лишь несколько «строительных блоков», из которых на этапе конечного проектирования и производства может быть собран итоговый процессор. Этот набор строительных блоков включает в себя процессорное ядро с L2 кэшем, L3 кэш, контроллер шины QPI, контроллер памяти, графическое ядро и так далее.

Необходимые «кубики» будут собираться в едином полупроводниковом кристалле и преподноситься в качестве решения для того или иного рыночного сегмента. Например, процессор Bloomfield, с которым мы встретимся в ближайшее время, включает в себя четыре ядра, L3 кэш, контроллер памяти и один контроллер шины QPI.

Серверные же процессоры с той же архитектурой, которые будут представлены в начале следующего года, будут включать до восьми ядер, до четырёх контроллеров QPI для объединения в многопроцессорные системы, L3 кэш и контроллер памяти. Бюджетные же модели семейства Nehalem, запланированные к выходу на вторую половину следующего года, будут располагать двумя ядрами, контроллером памяти, встроенным графическим ядром и контроллером шины DMI, необходимым для прямой связи с южным мостом. Это – далеко не все возможные варианты, мы привели именно их лишь в качестве иллюстрации чрезвычайной гибкости строения Nehalem.

Новые принципы дизайна платформ и процессоров – существенное, но не единственное нововведение, приходящее с внедрением новой микроархитектуры Intel. Многие изменения заложены и в главной составной части процессора – непосредственно в вычислительном ядре. Несмотря на то, что ядра процессоров Nehalem с точки зрения пользователя можно рассматривать лишь как улучшенный вариант микроархитектуры Core, в них реализовано много новых технологий и усовершенствований. Благодаря им процессоры Nehalem могут похвастать и увеличившейся «чистой» производительностью. Среди важных нововведений необходимо отметить появление технологии SMT (Simultaneous Multi-Threading) – аналога памятной технологии Hyper-Threading, позволяющей одновременно исполнять два вычислительных потока на одном ядре; добавление поддержки новых команд SSE4.2; повышение результативности механизма предсказания переходов; увеличение размера внутренних буферов; улучшение эффективности и скорости работы подсистемы кэш-памяти.
Подводя итог сказанному, обобщим основные отличительные черты процессоров, принадлежащих к поколению Nehalem:
Два, четыре или восемь ядер;
Усовершенствованные по сравнению с Core вычислительные ядра;
Технология SMT, позволяющая исполнять одновременно два вычислительных потока на одном ядре;
Три уровня кэш-памяти: L1 кэш размером 64 кбайта на каждое ядро, L2 кэш размером 256 кбайт на каждое ядро, общий разделяемый L3 кэш размером до 24 Мбайт;
Интегрированный контроллер памяти с поддержкой нескольких каналов DDR3 SDRAM;
Монолитная конструкция – процессор состоит из одного полупроводникового кристалла;
Технологический процесс с нормами производства 45 нм;
Возможность интегрирования в процессор графического ядра;
Новая шина QPI с топологией точка-точка для связи процессора с чипсетом и процессоров между собой;
Модульная структура.
Теперь, после краткого знакомства с общей концепцией новой микроархитектуры, давайте уделим больше внимания особенностям отдельных узлов процессоров, её использующих.
Усовершенствованное процессорное ядро
Несмотря на то, что процессоры семейства Nehalem преподносятся Intel как носители новой микроархитектуры, основная их часть – вычислительное ядро – по сравнению с Core изменилась не столь значительно, наибольшие улучшения кроются в инфраструктуре.

Однако не надо воспринимать это как обман со стороны производителя, Intel просто сосредоточился на ликвидации слабых сторон прошлой микроархитектуры, а само ядро к ним явно не относится. Действительно, вряд ли кто-то будет спорить с тем, что процессоры Core 2 – это прекрасный продукт, обладающий отличной удельной производительностью.
Впрочем, определённые улучшения в глубине процессорного ядра всё же сделаны были. Но инженеры при их разработке исходили не из простого желания увеличить быстродействие любой ценой, они хотели добиться лучшей эффективности Nehalem, позволяющей этому процессору более рационально задействовать все ресурсы. При этом, как и в случае с Atom, все изменения делались с оглядкой на тепловыделение – поэтому процессоры нового поколения должны стать и более привлекательными с точки зрения соотношения «производительность на ватт».
В соответствии с этой философией в первую очередь модификация затронула декодеры. Напомним, процессоры с микроархитектурой Core имели в своём распоряжении четыре декодера: три для простых инструкций и один – для сложных. При этом максимальное число x86-инструкций, которые декодируют эти процессоры за один такт, может доходить до пяти, так как благодаря технологии «Macrofusion» они способны обрабатывать некоторые пары команд (например, сравнение со следующим за ним условным переходом), как единую инструкцию.
В Nehalem количественный и качественный состав декодеров не изменился – но «Macrofusion» претерпела существенные изменения. Во-первых, увеличилось число пар x86 команд, декодируемых в рамках этой технологии «одним махом». Во-вторых, в Nehalem технология «Macrofusion» стала работать и в 64-битном режиме, в то время как в процессорах семейства Core 2 она могла активироваться лишь при работе процессора с 32-битным кодом. Таким образом, декодирование пяти, а не четырёх инструкций за такт, процессорам с новой микроархитектурой будет удаваться в большем числе случаев, чем их предшественникам.
Следующее усовершенствование, связанное с повышением продуктивности начальной части исполнительного конвейера, коснулось блока Loop Stream Detector. Этот блок появился впервые в процессорах с микроархитектурой Core и предназначался для ускорения обработки циклов. Определяя в программе циклы небольшой длины, Loop Stream Detector сохранял их в специальном буфере, что давало возможность процессору обходиться без их многократной выборки из кэша и предсказания переходов внутри этих циклов. В процессорах Nehalem блок Loop Stream Detector стал ещё более эффективен благодаря его переносу за стадию декодирования инструкций. Иными словами, теперь в буфере Loop Stream Detector сохраняются циклы в декодированном виде, из-за чего этот блок стал несколько похож на Trace Cache процессоров Pentium 4. Однако, Loop Stream Detector в Nehalem – это особенный кэш. Во-первых, он имеет очень небольшой размер, всего 28 микроопераций, во-вторых, в нём сохраняются исключительно циклы.

Работая над усовершенствованием микроархитектуры Core, инженеры Intel нашли пути и к улучшению и без того одного из лучших в индустрии механизма предсказания переходов. Однако ничего хитроумного здесь нет: в дополнение к уже имеющемуся блоку предсказания переходов был добавлен ещё один «предсказатель» второго уровня. Он работает медленнее, чем первый, но зато благодаря более вместительному буферу, накапливающему статистику переходов, обладает лучшей глубиной анализа. Надо заметить, что данное усовершенствование вряд ли даст сильный выигрыш в типичных приложениях, исполняемых на настольных компьютерах. Зато при серверной нагрузке двухуровневый блок предсказания переходов может оказаться очень эффективным. Это является прекрасной иллюстрацией универсальности микроархитектуры Nehalem: в ней можно встретить инженерные решения, ориентированные на нужды различных категорий пользователей.
Другое улучшение результативности механизма предсказания переходов было сделано переделкой блока Return Stack Buffer. Напомним, на этот блок возлагается задача правильного предсказания адресов возврата из функций. Однако процессоры прошлого поколения могли неверно предсказывать адреса возвратов из функций, например, при работе рекурсивных алгоритмов и переполнении соответствующего буфера. Новый же Return Stack Buffer, реализованный в Nehalem, эту проблему успешно устранил.
Существенно поработав над предварительными стадиями конвейера Nehalem, инженеры Intel оставили исполнительные устройства нового процессора без заметных изменений.

Также как Core 2, процессоры с микроархитектурой Nehalem способны отправлять на выполнение до шести микроопераций одновременно. Но в то же время разработчики увеличили размеры внутренних буферов стадии исполнения команд. В результате, процессоры Nehalem способны держать в ожидании выполнения в Reorder Buffer до 128 микроопераций – а это на 33 % больше, чем Core 2. Соответственно, Reservation Station, отправляющая микрооперации непосредственно на исполнительные устройства, расширена с 32 до 36 инструкций, а кроме того, увеличена и вместимость буферов и для работы с данными.
Все эти, казалось бы, небольшие изменения вызваны в первую очередь тем, что ядра новых процессоров поддерживают технологию SMT и способны исполнять одновременно по два вычислительных потока, нуждающихся в разделении ресурсов друг с другом. В итоге, Intel несколькими простыми микроархитектурными решениями увеличил КПД исполнительных устройств процессора, то есть нарастил производительность без существенных энергетических затрат.

Надо сказать, что возвращение в Nehalem технологии SMT – одно из самых существенных нововведений, способных положительно повлиять на производительность. В процессорах Pentium 4, где эта же технология преподносилась под маркетинговым именем Hyper-Threading, её включение давало средний прирост производительности на уровне 10 %. Новые же процессоры с микроархитектурой Nehalem должны получить от SMT больший выигрыш. Во-первых, они имеют в своём распоряжении подсистему памяти с гораздо более высокой пропускной способностью, которая способна эффективнее обеспечивать два вычислительных процесса потоками данных. Во-вторых, Nehalem может похвастать более «широкой» микроархитектурой, позволяющей обрабатывать большее число инструкций одновременно.

При этом необходимо заметить, что внедрение SMT в Nehalem, как, кстати, и в Pentium 4, не потребовало от инженеров существенного увеличения сложности процессора. Продублированы в ядре, фактически, лишь процессорные регистры и Return Stack Buffer. Все остальные ресурсы при включении SMT разделяются в процессоре между потоками динамически (например, Reservation Station или кэш-память) либо жёстко пополам (например, Reorder Buffer).
Как и в процессорах Pentium 4, активация SMT в Nehalem приводит к тому, что каждое физическое ядро видится операционной системой как пара логических ядер. Например, четырёхъядерный Nehalem будет распознаваться программным обеспечением как процессор с восемью ядрами.

Но памятуя о том, что активация SMT иногда может приводить и к снижению производительности, инженеры Intel сделали физические и логические ядра различимыми и неполноправными, позволяя программистам при необходимости самостоятельно решать вопрос о более правильном задействовании их ресурсов.
Для иллюстрации практическиго влияния описанных изменений на производительность мы решили сравнить скорость Nehalem с предшественником Penryn в нескольких простых синтетических тестах из пакета SiSoftware Sandra 2009. Ценность этих тестов заключается в том, что они совершенно не критичны к параметрам подсистемы памяти, что позволяет, основываясь на их показаниях, делать выводы о собственно процессорной микроархитектуре.
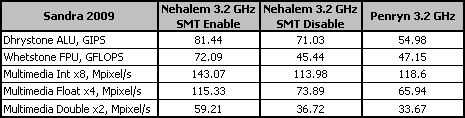
Действительно, преимущество новой микроархитектуры хорошо видно при включении SMT. Тесты Sandra 2009 качественно оптимизированы под многопоточность, поэтому совершенно не удивительно, что активация SMT улучшает показатели Nehalem на величину от 15 до 60 процентов. Однако если сравнивать результаты семейств Nehalem и Penryn, не беря в расчёт SMT, то получается, что процессор нового поколения способен показать лучшие результаты далеко не всегда. Всё зависит от характера нагрузки, что указывает на отсутствие революционных и универсальных улучшений в недрах нового ядра.

TLB и кэш-память
В самом начале статьи мы упомянули, что наибольшие отличия процессоров поколения Nehalem от предшественников следует искать не в глубине его ядер, а в интерфейсах и общей структуре. Изменения, произошедшие с кэш-памятью и TLB, полностью это подтверждают. Выглядят они куда более значительными, чем мелкие модификации во внутренних блоках процессорного ядра.
В первую очередь, инженеры Intel существенно увеличили размер TLB (Translation-Lookaside Buffer). Напомним, TLB – это высокоскоростной буфер, который используется для установления соответствия между виртуальными и физическими адресами страниц. Увеличение размера TLB, таким образом, позволяет повысить число страниц памяти, которые могут быть одновременно использованы без дополнительных дорогостоящих преобразований по таблицам трансляции адресов, находящимся в обычной памяти.
Более того, TLB в процессорах Nehalem стал двухуровневым. Фактически, к унаследованному от процессоров Core 2 TLB Intel просто добавила ещё один буфер второго уровня. При этом новый L2 TLB может похвастать не только высокой вместительностью, позволяющей сохранять до 512 записей, но и сравнительно низкой латентностью. Ещё одна особенность L2 TLB заключается в том, что он унифицирован и способен транслировать адреса страниц любого размера.
Очевидно, что изменения в системе TLB сделаны в первую очередь с прицелом на серверные приложения, активно оперирующие большими объёмами памяти. Однако и в «настольных» задачах увеличенное число вхождений TLB может оказать положительное влияние на быстродействие подсистемы памяти. Тем более, что при активации технологии SMT TLB обоих уровней динамически разделяется между виртуальными ядрами, так что возможность сохранять в этом буфере дополнительные записи явно не будет лишней.
Ещё одно нововведение, способное поднять скорость работы с подсистемой памяти в процессорах с микроархитектурой Nehalem, заключается в значительном ускорении работы инструкций, оперирующих невыровненными по строкам кэш-памяти данными. Первые робкие шаги в этом направлении были сделаны ещё в ядрах Penryn, но именно в Nehalem инженеры добились превосходного результата. Теперь SSE-инструкции, использующие в качество операндов выровненные 16-байтовые последовательности данных, работают с одинаковой скоростью, вне зависимости от того, какой вариант команды используется: для выровненных или для невыровненных данных. Поскольку большинство компиляторов транслирует код с использованием «невыровненных» версий инструкций, описанное усовершенствование способно положительно повлиять на скорость работы многих приложений, оперирующих медиа-контентом.
Однако ускорение работы с невыровненными данными и добавление TLB второго уровня – мелочи по сравнению со сделанной в процессорах Nehalem коренной переделкой системы кэш-памяти. От старой двухуровневой структуры кэш-памяти с общим на каждые два ядра L2 кэшем в новых процессорах остался только кэш первого уровня суммарным объёмом 64 кбайта, который делится на две равные части на области для хранения инструкций и данных. При этом, хотя строение L1 кэша в Nehalem и осталась старым, его латентность по сравнению с L1 кэшем Core 2 увеличилась на 1 такт. Произошло это в связи с внедрением в новых процессорах более агрессивных энергосберегающих режимов и, по мнению Intel, незначительно сказывается на итоговой производительности.
Использование же разделяемого L2 кэша, который показал себя очень эффективным решением в двухъядерных процессорах с микроархитектурой Core, оказалось весьма проблематичным при увеличении количества ядер. Поэтому в микроархитектуре Nehalem, предполагающей наличие в процессоре до 8 ядер, кэш второго уровня не является разделяемым. Каждое из ядер получило свой собственный L2 кэш со сравнительно небольшим объёмом 256 кбайт. Зато благодаря своей ограниченной ёмкости, этот кэш может похвастать в полтора раза более низкой латентностью, чем L2 кэш процессоров Core 2. Это отчасти компенсирует возросшую латентность L1 кэша в Nehalem.
К двум уровням кэша в Nehalem добавился и L3 кэш, который объединяет ядра между собой и является разделяемым. В результате, L2 кэш выступает буфером при обращениях процессорных ядер в разделяемую кэш-память, имеющую достаточно солидный объём. Так, например, четырёхъядерные процессоры с новой микроархитектурой, ориентированные на настольные компьютеры, будут использовать L3 кэш объёмом 8 Мбайт.

Использование трёхуровневой кэш-памяти невольно вызывает ассоциации с процессорами AMD с микроархитектурой K10, однако кэш-память Nehalem устроена всё же совершенно по-другому. Во-первых, L3 кэш в Nehalem работает на более высокой частоте, которая для первых представителей этого семейства будет установлена равной 2,66 ГГц. Во-вторых, Intel не стал отказываться от инклюзивности кэш-памяти, то есть от дублирования данных, хранящихся в кэшах первого и второго уровней, в L3 кэше. И это имеет вполне рациональное объяснение. Инклюзивный разделяемый кэш способен обеспечить в многоядерных процессорах более высокую скорость работы подсистемы памяти за счёт избыточного дублирования содержимого L1 и L2 кэшей всех ядер. В частности, при отсутствии в нём запрашиваемых одним из ядер данных, нет необходимости искать их в индивидуальных кэшах других ядер. А благодаря тому, что каждая строка L3 кэша снабжена дополнительными флагами, указывающими владельцев этих данных, не вызывает затруднений и процедура обратного изменения содержимого строки кэша. Так, если какое-то ядро модифицирует данные в L3 кэше, изначально принадлежащие другому (или другим) ядрам, то в этом случае обновляется содержимое L1 и L2 кэшей и этих ядер. Таким путём решается и проблема с избыточным межъядерным трафиком, направленным на поддержание когерентности инклюзивной кэш-памяти.
Измерения латентности кэш-памяти процессора Nehalem позволяют говорить о высокой эффективности предложенной схемы.
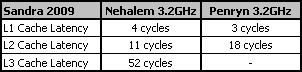
L2 кэш процессора Nehalem действительно обеспечивает крайне невысокую латентность. Кэш третьего уровня также способен показать очень хорошее время доступа, несмотря на свой относительно большой размер. К слову, вчетверо меньший эксклюзивный кэш третьего уровня процессоров AMD Phenom X4 по данным той же тестовой утилиты Sandra 2009 показывает примерно такую же латентность – 54 цикла. Однако ввиду более низких тактовых частот процессоров AMD, время доступа L3 кэша у процессоров Phenom оказывается ощутимо больше, чем у Nehalem.
Несмотря на кардинальный пересмотр системы кэширования, инженеры Intel не стали менять алгоритмы работы блоков предварительной выборки, они в Nehalem целиком позаимствованы из Core 2. Это означает, что упреждающая выборка данных и инструкций производится только в кэш-память первого и второго уровня. Тем не менее, даже при использовании старых алгоритмов, результативность работы блоков предварительной выборки улучшилась. Объясняется это тем, что L2 кэш в Nehalem индивидуален для каждого ядра, а при такой организации кэш-памяти гораздо легче отслеживать шаблоны в обращениях. Кроме того, благодаря появлению L3 кэша работа блока предварительной выборки не наносит существенного ущерба пропускной способности шины памяти. Именно поэтому в серверных вариантах процессоров Nehalem блоки предварительной выборки больше не будут отключаться, как это делалось в процессорах Xeon, основанных на микроархитектуре Core.
Новые SSE4.2 инструкции
В новой микроархитектуре Nehalem Intel продолжила взятый ранее курс на увеличение числа поддерживаемых SIMD инструкций. Пополненный набор команд расширился за счёт семи новых инструкций и получил название SSE4.2 (обозначение SSE4.1 использовалось для системы SIMD команд процессоров Penryn). При этом Intel специально заостряет внимание на том, что введённые в набор SSE4.2 инструкции ориентированы не столько на ускорение обработки потокового медиа-контента, сколько на иные цели. Именно поэтому новые, введённые в Nehalem, инструкции получили также условное обозначение ATA (Application Targeted Accelerators).
Концепция ATA преподносится так, что современные технологические процессы позволяют задействовать часть процессорных транзисторов не только на универсальные функциональные блоки, но и на специфические нужды, поднимая быстродействие конкретных задач.
Так, в соответствии с этой концепцией в SSE4.2 добавлено пять инструкций, предназначенных для ускорения синтаксического анализа XML-файлов. Также с помощью этих же инструкций возможно увеличение скорости обработки строк и текстов. Ещё две новые инструкции из набора SSE4.2 нацелены на совершенно иные приложения. Первая из них, CRC32, аккумулирует контрольную сумму CRC32c, а вторая, POPCNT, подсчитывает число ненулевых бит в источнике. Эти команды также могут найти широкое применение в различных прикладных и сетевых приложениях.
Интегрированный контроллер памяти
Nehalem стала первой интеловской микроархитектурой, предполагающей интеграцию контроллера памяти внутрь процессора. Казалось бы, здесь инженеры Intel позаимствовали идею своих коллег из AMD, которые встраивают контроллер памяти внутрь процессоров начиная с 2003 года. Однако это не совсем так, поскольку первыми процессорами с интегрированным контроллером памяти должны были стать так и не вышедшие Intel Timna, работа над которыми активно велась в 1999 году. Кроме того, обвинения в плагиате следует отмести и потому, что разработанный Intel для Nehalem контроллер памяти сильно отличается от контроллера, эксплуатируемого в существующих процессорах AMD. Подход Intel к проблеме оказался куда более масштабным.
Главное свойство контроллера памяти процессоров семейства Nehalem – гибкость. Учитывая модульный дизайн всего перспективного семейства процессоров, которое может содержать сильно различающиеся по характеристикам и рыночному позиционированию продукты, Intel предусмотрела возможность не только включать или отключать поддержку буферизированных модулей, но и варьировать число каналов и скорость памяти.
При этом первые процессоры с микроархитектурой Nehalem, которые будут выпущены в четырёхъядерном варианте, получат трёхканальный контроллер памяти с поддержкой DDR3 SDRAM. Таким образом, настольные системы, построенные на новых процессорах, смогут похвастать непревзойдённой пропускной способностью подсистемы памяти, которая в случае использования трёх модулей DDR3-1067 достигнет 25,6 Гбайт/с.
Впрочем, основное преимущество переноса контроллера DRAM в процессор заключается не столько в росте пропускной способности, сколько в уменьшении латентности подсистемы памяти. Несмотря на то, что Intel предлагает использовать с новыми процессорами DDR3 память, отличающуюся относительно высокой латентностью, задержки при обращении Nehalem к памяти будут в любом случае ниже, чем в системах, основанных на процессорах Core 2 и использующих DDR3 SDRAM (и, наверняка, DDR2 SDRAM).
Для подтверждения этих слов хотелось бы привести данные, полученные при измерении практических параметров подсистемы памяти системы на базе Nehalem в тестовой утилите Everest 4.60.

Собственно, даже работая в одноканальном режиме, контроллер памяти Nehalem способен показать лучшую производительность, чем контроллер памяти сегодняшних LGA775 платформ. Это совершенно закономерный результат, так как на пути между процессором и памятью в системах нового поколения нет никаких промежуточных устройств – в то время как ранее за работу с памятью отвечал северный мост чипсета, который вносил собственные весьма существенные задержки, вызванные необходимостью синхронизации шин памяти и FSB.
Ещё одно косвенное преимущество встроенного в процессор памяти заключается в том, что его функционирование теперь не зависит ни от чипсета, ни от материнской платы. В результате, Nehalem будет показывать одинаковую скорость работы с памятью при работе в платформах различных разработчиков и производителей.
Шина QPI
Казалось бы, интеграция контроллера памяти должна разгрузить процессорную шину, которая в этом случае оказывается освобождена от передачи данных между процессором и памятью. И это отчасти верно, но только для однопроцессорных систем. Микроархитектура Nehalem же универсальна, её предполагается использовать как в настольных и мобильных, так и в серверных продуктах. Поэтому при разработке новой микроархитектуры Intel уделила внимание и проектированию новой процессорной шины, которая бы оказалась применима и в многопроцессорных системах, обеспечивая необходимую пропускную способность и масштабируемость. Впрочем, иного выхода у инженеров и не было, так как привычная шина FSB в данном случае оказывается неприменима: многопроцессорные системы, построенные на процессорах со встроенными контроллерами памяти, должны использовать «распределенную» модель памяти NUMA (Non-Uniform Memory Access), а, следовательно, нуждаются в прямом и высокоскоростном соединении между процессорами.
Для решения этой задачи был построен специальный последовательный интерфейс CSI (Common System Interface) с топологией точка-точка, переименованный впоследствии в QPI (QuickPath Interconnect). С технической точки зрения шина QPI представляет собой два 20-битных соединения, ориентированных на передачу данных в прямом и обратном направлении. 16 бит предназначаются для передачи данных, оставшиеся четыре – носят вспомогательный характер, они используются протоколом и коррекцией ошибок. Эта шина работает на максимальной скорости 6,4 миллиона передач данных в секунду (GT/s) и имеет, соответственно, пропускную способность 12,8 Гбайт/с в каждую сторону или 25,6 Гбайт/с суммарно.

На сегодня пропускная способность QPI такова, что эту шину можно смело назвать самой скоростной процессорной шиной. Так, старая Quad Pumped Bus достигает суммарной пиковой скорости 12,8 Гбайт/с только при частоте 1600 МГц. Похожая же на QPI шина HyperTransport 3.0, применяемая в современных процессорах AMD, может похвастать пиковой скоростью лишь 24 Гбайт/с.
В зависимости от рыночного ориентирования, процессоры с микроархитектурой Nehalem могут комплектоваться одним или несколькими интерфейсами QPI. В итоге в многопроцессорной системе каждый из процессоров может иметь прямую связь со всеми остальными процессорами для снижения латентности при обращении к памяти, подключенной к «чужому» контроллеру. Модели же для однопроцессорных настольных систем будут снабжаться единственным QPI, который будет использоваться для связи с набором логики материнской платы.

Управление питанием и Turbo-режим
Многие изменения, реализованные инженерами Intel в процессорах Nehalem, связаны с оптимизацией микроархитектуры под врождённое многоядерное строение. Поэтому необходимость пересмотра системы управления питанием процессора назрела сама собой. Многоядерные процессоры с микроархитектурой Core очень неэкономичны с той точки зрения, что управление энергосбережением в них происходит по единому алгоритму, который практически не учитывает состояния отдельных ядер. И поэтому, например, нередки ситуации, когда одно находящееся под вычислительной нагрузкой ядро препятствует переходу в энергосберегающие состояния остальных ядер, несмотря на то, что они, фактически, простаивают.
Именно поэтому микроархитектура Nehalem предполагает наличие в процессоре ещё одного важного блока – PCU (Power Control Unit). Этот блок представляет собой встроенный в процессор программируемый микроконтроллер (то есть, по сути процессор в процессоре), целью которого является «интеллектуальное» управление потреблением энергии. Неудивительно, что при этом PCU имеет достаточно сложную конструкцию: на его реализацию ушёл примерно 1 миллион транзисторов.

Основным предназначением PCU является управление частотой и напряжением питания отдельных ядер, для чего этот блок имеет все необходимые средства. Он получает от всех ядер со встроенных в них датчиков всю информацию о температуре, напряжении и силе тока. Основываясь на этих данных, PCU может переводить отдельные ядра в энергосберегающие состояния, а также управлять их частотой и напряжением питания. В частности, PCU может независимо друг от друга отключать неактивные ядра, переводя их в состояние глубокого сна, в котором энергопотребление ядра приближается к нулевой отметке.

Для реализации такой возможности инженеры и технологи Intel разработали специальный полупроводниковый материал, посредством которого стало возможно независимое отключение ядер от общей шины питания. Главное преимущество этой технологии состоит в том, что управление питанием отдельных ядер осуществляется целиком внутри процессора и не требует усложнения схемы конвертера питания на материнской плате.
Что же касается общих для всех ядер процессорных блоков, таких как контроллеры памяти и интерфейса QPI, то они переходят в энергосберегающие состояния, когда в состоянии сна находятся все процессорные ядра.
Наличие в процессоре контроллера, способного независимо управлять состоянием процессорных ядер, позволило Intel реализовать и ещё одну интересную технологию, получившую название Turbo Boost Technology. Эта технология вводит понятие турбо-режима, в котором отдельные ядра могут работать на частоте, превосходящей номинальную, то есть разгоняться. Основной принцип Turbo Boost Technology состоит в том, что при переходе отдельных ядер в энергосберегающие состояния снижается общее энергопотребление и тепловыделение процессора, а это в свою очередь позволяет нарастить частоты остальных ядер без риска выйти за установленные рамки TDP.
Фактически, прообраз этой технологии уже был реализован в двухъядерных мобильных процессорах поколения Penryn, однако в Nehalem её развитие продвинулось ещё дальше. В новых процессорах, если нет риска выйти за границу типичного энергопотребления и тепловыделения, PCU может повышать частоты процессорных ядер на один шаг выше номинала (133 МГц). Это может происходить, например, при слабо распараллеленной нагрузке, когда часть ядер находится в состоянии простоя.

Более того, при соблюдении описанных условий, частота одного из ядер может быть увеличена и на два шага выше номинала (266 МГц).

Следует отметить, что необходимым условием включения турбо-режима вовсе не является переход одного или нескольких ядер в энергосберегающее состояние. Это – всего лишь один из возможных сценариев. Так как PCU имеет все средства для получения данных о фактическом состоянии процессорных ядер, турбо-режим может задействоваться и в тех случаях, когда все ядра работают, но нагрузка на часть из них невелика.
Большим преимуществом Turbo Boost Technology является её полная прозрачность для операционной системы. Эта технология реализована исключительно аппаратными средствами и не требует использования никаких программных утилит для своей активации.
Чтобы посмотреть, как это выглядит на практике, мы проследили за состоянием четырёхъядерного процессора Nehalem с номинальной частотой 3,2 ГГц при запуске от одного до восьми вычислительных потоков, создаваемых утилитой Prime95.

Как видно на приведённой анимированной иллюстрации, при отсутствии нагрузки срабатывает технология Intel Enhanced SpeedStep – частота процессора сбрасывается до 1,6 ГГц. Запуск одного потока приводит к активации единственного ядра, что позволяет процессору поднять собственный множитель с 24x до 26x, тем самым увеличивая тактовую частоту до 3,46 ГГц. Два потока увеличивают загрузку процессора настолько, что PCU находит возможным лишь повышение частоты до 3,33 ГГц. Такая ситуация остаётся неизменной и при дальнейшем росте количества потоков – вплоть до пяти. И только шестой поток, поднимающий загрузку процессора до 75 %, приводит его частоту к положенной штатной величине 3,2 ГГц. Иными словами, Turbo Boost Technology представляется отнюдь не эфемерной вещью, её эффект более чем осязаем.
Первые Nehalem – это Bloomfield
Первыми серийными процессорами, основанными на новой микроархитектуре Nehalem, станут настольные модели, известные под кодовым именем Bloomfield. Эти процессоры будут иметь четырёхъядерное строение. Помимо процессорных ядер, в полупроводниковый кристалл Bloomfield будет включён кэш третьего уровня объёмом 8 Мбайт, трёхканальный контроллер памяти с поддержкой DDR3 SDRAM и один интерфейс QPI. Получившийся процессор будет состоять из 731 млн. транзисторов и производиться по 45-нм технологическому процессу с применением диэлектрика с высокой диэлектрической проницаемостью и металлических затворов. Площадь кристалла процессора составит 263 кв. мм.

Процессоры Bloomfiled будут продаваться под именем Core i7. Частоты первых моделей, анонс которых намечен на середину ноября, составят 3,2, 2,93 и 2,66 ГГц, а их типичное тепловыделение будет ограничиваться величиной 130 Вт.

Учитывая, что процессоры с микроархитектурой Nehalem снабжаются встроенным контроллером памяти и новым высокоскоростным интерфейсом QPI, они изменят свою упаковку. Так, Core i7 будут выпускаться в LGA1366 форм-факторе, имеющем существенно больший по сравнению с LGA775 размер – 42,5 x 45 мм.

Соответственно, для установки Core i7 потребуются новые материнские платы, в основе которых пока что может использоваться лишь единственный поддерживающий интерфейс QPI набор логики – Intel X58 Express.

Более подробные характеристики процессоров Core i7 приводятся в таблице.
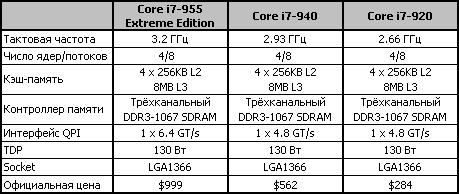
Основной особенностью модели Extreme Edition, помимо более высокой тактовой частоты, станет дружественность к оверклокерам. Этот процессор будет иметь незафиксированные коэффициент умножения и множитель, задающий частоту памяти.

Очевидно, что модели семейства Core i7 займут верхнюю часть рынка процессоров для настольных компьютеров. Там они сменят старшие модели Core 2 Quad и Core 2 Extreme, поставки которых вскоре будут прекращены. Следует заметить, что модельный ряд процессоров Core i7, состоящий всего из трёх продуктов, сохранится в неизменном виде достаточно продолжительный период времени. Согласно имеющимся планам Intel, перемены ожидаются только в середине следующего года, когда разновидности Nehalem начнут предлагаться по более демократичным ценам в качестве общеупотребительных, а не топовых решений.
Приход же процессоров с новой микроархитектурой в серверные системы и рабочие станции ожидается в начале следующего года, а их появление в составе мобильных платформ – во второй половине 2009 года.
Заключение
Безусловно, выход процессоров Nehalem станет главным событием этого года на компьютерном рынке. Компания Intel умело подогревала интерес к своей новой микроархитектуре и добилась неплохих результатов: различными измышлениями и слухами об этих процессорах переполнены любые издания, посвященные информационным технологиям.
Но мы повременим с оптимистичными отзывами и хотим предупредить читателей, что, несмотря на все преимущества новой микроархитектуры, от процессоров Core i7 не следует ожидать слишком многого. Во-первых, значительная часть сделанных нововведений и улучшений направлена в первую очередь на серверные задачи, и пользователи настольных систем вряд ли почувствуют их «на своей шкуре». Во-вторых, основной упор при проектировании Nehalem делался всё-таки не на увеличение «чистой» производительности, а на ликвидацию узких мест в платформе, которые особенно чувствовались опять-таки в серверных приложениях.
Основной же выигрыш в быстродействии, который могут получить владельцы настольных систем, основанных на процессорах Core i7, будет обуславливаться тремя факторами. Во-первых, поддержкой технологии Turbo Boost, благодаря которой процессор достаточно часто будет переходить на частоту, превышающую номинальную. Во-вторых, наличием интегрированного контроллера памяти, обеспечивающего как непревзойдённую пропускную способность, так и весьма впечатляющую латентность. И, в-третьих, поддержкой технологии SMT, положительное влияние которой можно будет наблюдать в первую очередь при многопоточной нагрузке.
Хотя с одной стороны эти факторы способны ощутимо поднять уровень быстродействия новых процессоров, с другой – их влияние сильно зависит от характера возлагаемой на процессор нагрузки. Поэтому в некоторых задачах процессоры Core i7 могут показаться не столь революционными, тем более, что само вычислительное ядро претерпело лишь незначительные изменения по сравнению с «классическими» представителями микроархитектуры Core. А это значит, что такого же восторга, как в своё время вызвало появление процессоров Core 2 вслед за Pentium 4, новые Core i7 явно не пробудят.
Настоящую же революцию должен будет совершить предстоящий приход Nehalem в сервера. И хотя инертность этого рынка практически наверняка не даст им быстро захватить лидерство, несмотря на все преимущества, появление серверов, использующих процессоры с новой интеловской микроархитектурой, должно будет поднять привлекательность соответствующих решений на новый уровень.
В итоге, с точки зрения рынка настольных процессоров, Nehalem вполне можно охарактеризовать как очередное обновление микроархитектуры Core, происходящее по эволюционной ветви Conroe – Penryn – Nehalem. Однако и такого развития событий вполне достаточно для того, чтобы Intel продолжила прочно удерживать позиции лидера микропроцессорного рынка. Тем более, что концепция развития «Tick-Tock» продолжает своё существование, а значит, уже через год нас будет ждать перевод Nehalem на 32-нм технологический процесс, а через два года – новая микроархитектура.
Продолжение: «Новый хит Intel: процессоры Core i7»
Уточнить наличие и стоимость процессоров Intel Core i7
Уточнить наличие и стоимость материнских плат для Intel Core i7
Другие материалы по данной теме
Недорогие четырёхъядерники: сравнительное тестирование
Бюджетные процессоры Intel: Core 2 Duo E7300 и Pentium Dual-Core E5200
Битва экономичных процессоров: выбираем основу для неттопа



© 1998-2023 fcenter.ru | Россия
© 1998-2023 fcenter.ru | Россия