Ваш город: Москва
Another world
- нападать будем маленькими группками
по пять миллионов человек. А потом
в бой пойдут танки, танки, танки…
- Что, все три?!
Анекдот (с)
Распевка
Цитата из достаточно известного анекдота вынесена в эпиграф не случайно: в то время как сторонники процессоров Intel и AMD ломают копья, перетряхивая пыльные тома спецификаций в поисках свежих аргументов, некоторые производители умудряются продавать технику совсем другого сорта. Совсем другого вида. И совсем других ТТХ – тактико-технических характеристик. Вполне естественно, что это рождает ряд вопросов: что же это за техника? Лучше она или хуже, чем привычная для нас? Есть ли у нее уникальные характеристики? И вообще, зачем люди покупают Apple Macintosh (в дальнейшем Mac-и)?
Да, эта статья будет посвящена Mac-ам. Точнее, их "сердцу", микропроцессорам Mac-ов. Данная статья кажется необходимой хотя бы потому, что уже довольно долго автор сталкивается со всевозможными [практически религиозными] верованиями в этой области. Начиная от рассказов о том, что "Mac-и – они совсем другие", и заканчивая историями о невыносимо производительной архитектуре. Такой, что конкуренты и за десяток лет не сумеют догнать. Тем не менее, среди списка лидеров по SPEC CPU 2000 автор Mac-ов практически не видел (вернее, совсем не видел). Следовательно, в чистой производительности микропроцессоры этих компьютеров отнюдь не лидеры. Почему же существуют слухи о "принципиально другой архитектуре"? Почему до сих пор есть мнение, что именно Mac-и лучше всего подходят, например, в качестве машины для полиграфии? Справедливы ли рекламные заверения Apple о лидерстве в обработке графики?
Есть и еще один резон в такой статье: не так уж часто мы останавливаемся посмотреть: что же творится вокруг. Чем, кроме х86 во всех своих модификациях, порадует индустрия? Автору кажется, что посмотреть на микропроцессоры, которые сегодня являются уже не столько конкурентами х86, сколько "параллельным миром", было бы вполне интересно. Вот для того, чтобы подчеркнуть отсутствие прямой конкуренции, статья и была названа подобным образом.
15 октября, больше года назад, автор прочитал об анонсе нового процессора PowerPC, PowerPC970. И вот, спустя некоторое время после анонса, наступил самый что ни на есть удачный момент посмотреть, что же из этого анонса вышло? Удалось ли сделать новый прорыв (ведь это буквально фирменная черта компьютеров Apple), или же новый Mac всего лишь "продолжает дело" своих предшественников?
Куплет первый: с чего начинается Родина
Для начала давайте припомним, из чего же состоит компьютер. Тем более, что функционально блоки, что в х86-совместимых компьютерах, что в Mac-ах совершенно одинаковы. Как бы ни отличались названия конкретных деталей, всегда есть:
- Корпус (блок питания);
- Микропроцессор;
- Шина;
- Память;
- Видеокарта;
- HDD, CD Drive (DVD Drive);
- Операционная система и прикладные программы.
Пробежимся по пунктам. Пункт 1, безусловно, является яркой визитной карточкой Apple. Именно безукоризненные дизайнерские решения долгое время были эксклюзивным почерком Mac-ов. Достаточно вспомнить iMac, где впервые был применен прозрачный корпус, через который видно внутреннее устройство. Индустрия с радостью подхватила новое решение: хотя в данный момент подобный вид устройства способен вызвать у менеджера разве что чувство тошноты и пресыщения, но в свое время это дизайнерское решение гремело. Можно резюмировать, что машины от Apple всегда отличались элегантностью и красивыми корпусами. Собственно, частично именно под действием концепций Apple стал облагораживаться дизайн современных компьютеров, теперь это далеко не всегда прямоугольные коробки унылого серого цвета. Будем считать, что это "первый из трех танков", упомянутых в эпиграфе.
Временно пропустив пункты 2, 3, 4 (они будут темой сегодняшнего разговора), быстро переберем оставшиеся.
Итак, видеокарты, пункт 5. Поначалу видеокарты у Mac-ов сильно отличались от соответствующих видеокарт для PC, так что в этом месте у двух архитектур не было ничего общего. Со временем PC сильно вырвались вперед, а Mac-и заметно отстали по возможностям своих видеоадаптеров. Это и понятно, на руку владельцам PC играл такой фактор, как огромное число трехмерных игрушек, предъявляющих все более серьезные требования к видеокартам. Этот "двигатель" постоянно создавал спрос на все более быстрые видеокарты и стимулировал разработку все более быстрых видеоадаптеров. Впрочем, с появлением на Mac-е шины PCI, а затем и AGP, тот практически догнал своего "брата" – наиболее быстрые модификации видеокарт есть и для Mac-ов, либо отставание [по моделям] не слишком велико. Если подытожить, то Mac скорее отстает, нежели опережает PC в этом пункте.
Жесткие диски…. Когда-то Mac-и базировались на жестких дисках стандарта SCSI, затем SCSI-2…. В то время жесткие диски этого стандарта настолько превосходили в скорости своих убогих IDE-собратьев, что, скорее всего, именно это и породило легенду о высочайшей производительности Mac-ов. В общем-то, на тот момент времени это была отнюдь не легенда, а быль: Mac-и тогда действительно сильно превосходили PC в аппаратной части. Правда, рынок оказался неумолим – из-за постоянного снижения цены на PC, вызванного открытыми стандартами и высочайшей конкуренцией, цена на Mac-и, первоначально вполне соотносимая с PC, стала "зашкаливать". И со временем разрыв все увеличивался…. Это привело к тому, что спрос стал падать, и, в свою очередь, продавалось меньше машин, что еще больше увеличивало себестоимость. Процесс грозил стать необратимым, компанию Apple многие для себя практически "похоронили", когда корпорация, наконец, одумалась. Ей удалось остановиться буквально "одной ногой над пропастью". Правда, расплачиваться за это пришлось многими из тех отличий, которые ранее создавали образ Mac. Apple решительно распростилась со SCSI HDD и периферией, с закрытыми стандартами AppleTalk, с собственными шинами – все это в пользу ставших индустриальными стандартами E-IDE, PCI, AGP. Причем успела компания это сделать буквально в последний момент, находясь тогда в весьма сложном финансовом положении.
Другими словами, на сегодня практически половина комплектующих в Apple и PC совпадают, что весьма пошло на пользу такому потребительскому параметру, как стоимость Mac-а. Ну а имидж "отличного от других" решения можно сформировать и по-другому, что Apple вполне убедительно доказала.
Еще одним ключевым отличием Mac-а стала его операционная система. Автор склонен считать, что именно это и является "вторым из трех танков", вынесенных в эпиграф; тем самым отличием, которое и создало Apple ее преданных поклонников и покупателей. В самом деле, Apple практически первой массово применила графическую операционную систему (исследовательский центр "Xerox" не учитываем, невзирая на его приоритет по времени; все же тогда "в массы" его исследования не пошли, хотя, безусловно, стали основой и движущей силой многих новинок). И таких [ключевых] нововведений за Apple числится действительно немало! Правда, оценить эту операционную систему достаточно сложно, поэтому опустим какие-либо оценки эффективности, производительности, удобства и другие сложно взвешиваемые и практически не подверженные численному учету характеристики. Достаточно того, что операционная система есть, и она является одним из основных отличий Mac-а от РС.
И вот осталась наша любимая часть: микропроцессор, шина, память. То, что характеризуют емким словом "платформа". Именно ей и посвящена сегодняшняя статья.
Куплет второй: гладко было на бумаге, да забыли про овраги
Для начала напомним, что применение этого микропроцессора широко освещалось в Apple, как нечто революционное: дескать, впервые 64 бита на десктопе! Ну, тут Apple немного (и, в общем-то, безобидно) слукавила – как бы там ни было, но первой она оказалась только по причине того, что выход Athlon 64 от AMD оказался отложенным. Вернее сказать, этот процессор вышел вначале на серверный рынок. Так Apple и оказалась в "первопроходцах" истории "64 бита в каждый десктоп". Ну и, естественно, не обошлось без приключений. Оказалось, что ошибки и проблемы совместимости – прерогатива не только Microsoft. Более того, хваленая "безглючность" и "беспроблемность" платформы от Apple также оказалась скорее легендой – просто до поры до времени приносила "дивиденды" значительно более узкая и упорядоченная аппаратная платформа у Apple. Естественно, что создать и отладить операционную систему для заданного сравнительно небольшого набора оборудования гораздо легче, чем создать операционную систему, обязанную функционировать практически на любом наборе железок. Пока платформа Mac-ов была более-менее однородной, это не бросалось в глаза. Но стоило появиться платформе, действительно сильно отличающейся от предыдущих платформ (хотя бы той же 64-битностью), как возникли типичные проблемы переходного периода. Об этом, кроме всего прочего, говорит один "мелкий", но показательный факт. Выпуск Mac OS X, который должен был стать триумфом, как-то очень быстро и незаметно сменился на OS 10.1, 10.2, нынешняя редакция носит имя 10.3. В общем, триумфа не получилось – все еще далеко не все популярные программы переведены на новую операционную систему. А стабильность старых приложений, работающих в соответствующем режиме совместимости, далека от идеала. Да и производительность далеко не так убедительна, как обещалось ранее. Другими словами, процесс перехода не удалось сделать гладким и незаметным. Впрочем, со временем положение все же выправится – рано или поздно, но приложения портируют, операционную систему отладят, ошибки подлечат.
Мы же, оставаясь за рамками идеологических споров "нужны ли на десктопе 64 бита", укажем несколько полезных применений этой технологии: большая виртуальная память, большее физическое адресное пространство и некоторые специальные применения. Например, в криптографии использование 64-битных операндов частенько позволяет заметно (иногда на порядок и более) сократить число операций, а, значит, и длительность расчетов.
Да и не будем забывать, что количество оперативной памяти в современных компьютерах постепенно приближается к пределу адресации для 32-битных процессоров (4GB при плоской модели памяти). Другими словами, чтобы потом не городить лихорадочных и срочных решений, проще заблаговременно озаботиться вопросами достаточной разрядности. Засим кратко мнение автора о 64-битности можно выразить так: почему бы нет? Мешать она ничему особо не мешает, а помочь иногда способна довольно существенно. Посему не возражаем. Но, как выяснилось, активно возражает "кое-кто другой". Впрочем, об этом ниже.
Таким образом, на сегодня большинство наиболее современных процессоров (по маркам, а не по количеству) является 64-битными. Сюда относятся практически все RISC (MIPS, Alpha, HP PA_RISC), post-RISC (Itanium, с определенными оговорками Transmeta) и часть x86 процессоров: Opteron (Athlon 64). Фактически, сугубо 32-битными из современных процессоров остались разве что Pentium 4 (ведь даже Xeon в какой-то степени можно условно считать 36-битным процессором). Тем интереснее, кстати, выглядит ситуация, которая складывается вокруг тестов SPEC CPU 2004. Как доносится из весьма осведомленных источников, оргкомитет SPEC уже практически определился с составом алгоритмов, которые будут входить в этот тест. Более 40 подтестов, требуемый объем оперативной памяти порядка 2GB (!), время однократного прохода порядка суток. Процедура тестирования станет, таким образом, намного более напряженной. Но гораздо интереснее то, что алгоритмов, сильно выигрывающих от перехода на 64 бита, в SPEC CPU 2004 не будет. Вот это сюрприз…. Они, оказывается, "малоинтересны" – и это в то самое время, когда процессоры, поддерживающие 64 бита, как раз появляются на десктопах. Это в то время, когда ВСЕ производители процессоров имеют 64-битные процессоры. Это в то время, когда только один производитель не предлагает 64-битных процессоров в своих наиболее массовых изделиях. Не нужно быть семи пядей во лбу, чтобы понять, о ком говорит автор. Да, к сожалению, компания Intel заняла в чем-то понятную, но крайне неприятную позицию "а Баба Яга против". Благодаря ее давлению (и праву "вето") комитет SPEC утвердил набор алгоритмов, которые ничего, кроме недоумения, не вызывают. Безусловно, Intel, которая является одним (и, похоже, самым крупным) из источников финансирования этого комитета, вправе отстаивать свои интересы. Но хотелось верить, что в процессе "отстаивания" все-таки будет некая грань, которую не перейдут. Похоже, надежда оказалась тщетной. Ситуация вокруг новой версии SPEC CPU 2004 очень похожа (автору даже хочется применить словосочетание "слишком похожа") на историю с "оптимизацией" SYSMark 2003, который после проведенной "оптимизации" стал слишком пристрастным к одной процессорной архитектуре и слишком ….неоднозначным ко всем остальным. Не получилось бы так со SPEC тестами…. До сих пор это были очень уважаемые межплатформенные тесты, на результаты которых могли ориентироваться специалисты. Если эта ситуация изменится, то практически не останется тестов, которые бы смогли занять это место – никакие другие тесты не являются настолько авторитетными, ни для каких других тестов не накоплено такой большой документальной базы….
Будем надеяться, что автор был просто обманут (неверно информирован), и ничего подобного не произойдет. В противном случае тестами SPEC придется перестать пользоваться – они более не будут адекватным отражением применяемых в программировании алгоритмов, а превратятся в инструмент маркетинга. Для, не побоимся этого слова, впаривания своей продукции. Потому что продукция, которую не нужно впаривать, не нуждается в таких "методах маркетинга", от которых буквально за версту слишком уж попахивает подлогом и нечистоплотностью.
Куплет третий: я свежий ветер, огонь крылатый
Но вернемся к рассмотрению платформы. На очереди микропроцессор, мозг любого компьютера. Что изменилось в текущем микропроцессоре IBM PowerPC970 по сравнению с его [хронологическим] предшественником, Motorola G4+? Кстати, обратим внимание, что поменялся основной поставщик микропроцессоров для Apple – достаточно редкое событие в мире бизнеса. Неужели эта микросхема настолько хороша? Что она может предложить по сравнению с новейшими микросхемами из мира х86?
Начнем с общих характеристик: площади, частоты, тепловыделения. Построим таблицу, в которой сравним PowerPC970 с другими современными процессорами:

* – максимальное тепловыделение для всей платформы на сегодняшний момент. Тепловыделение данного процессора нам найти не удалось. По некоторым источникам, максимальное тепловыделение данного процессора находится на уровне 70Вт.
Очевидно, что PowerPC970 заметно ближе к современным х86 процессорам, нежели его предшественник. А в некоторых характеристиках (например, в тепловыделении) довольно заметно их превосходит. Не в последнюю очередь благодаря сниженному напряжению питания (вообще, технологическая база у IBM одна из лучших в индустрии).
Посмотрим, что у нас с количеством и организацией кэшей:

* - как мы помним, Intel не публикует объем Trace cache в KB…. По косвенным признакам (делая определенные допущения о длине микрооперации) можно приблизительно оценить объем этого кэша в 80КВ – 120КВ! С другой стороны, поместиться в этом объеме кэша может заметно меньшее, чем обычно, количество команд: все дело в том, что команды в Trace cache хранятся в уже декодированном виде, а в таком виде они заметно "распухают". Видимо, именно в этом причина того, что Intel вовсе и не вспоминает, что у кэша бывает объем в КВ, а не только в микрооперациях. А, может быть, все гораздо проще, и корпорация просто пытается остаться корректной, не складывая яблоки с апельсинами. Как бы там ни было, очень приблизительно емкость этого кэша мы можем подсчитать при помощи следующей оценки: средняя длина х86-команды составляет 3-4 байта. Пусть для определенности 4 байта. Большая часть х86 инструкций раскладывается на две микрооперации. То есть, 12 000 микроопераций соответствуют примерно 6 000 х86-команд. Примерно столько их помещается [в стандартном виде] в 24КВ кэш данных. Подчеркнем, что эта оценка крайне приблизительна. Причем, похоже, это оценка сверху для емкости Trace cache.
Занятно, что объем кэша команд в этой архитектуре больше, чем объем кэша данных. Впрочем, так частенько бывает в RISC архитектурах (и, например, в NexGen и K5, которые внутри были RISC процессорами); вторая сторона простоты команд (которую так хвалят инженеры), оборачивается тем, что объем кода оказывается заметно большим, нежели сравнимый по функциональности х86-код.
Также интересно, что для кэша инструкций используется наиболее простая схема организации, "прямое отображение". При этом каждая строка кэша имеет длину 128 байт и состоит из 4 секторов по 32 байта. Каждый такт один сектор (32 байт) может быть либо записан, либо считан из кэша. Для L1 Data cache все интереснее: через два порта могут быть прочитаны два сегмента по 8 байт, и 8 байт могут быть записаны через третий порт. Все это одновременно, в течение одного такта, и без взаимной блокировки.
Кэш L2 также имеет строку длиной 128 байт, схема обновления его содержимого – стандартная в отрасли Pseudo LRU, 7 bit.
Что же касается выбранной схемы "прямого отображения" для работы Instruction Cache L1, то объяснения этому факту у автора нет. По-видимому, инженеры IBM сочли, что даже такая схема обеспечивает приемлемый показатель точности попаданий в кэш (cache hits). А, быть может, просто по возможности упрощали схемотехнику кристалла. И без того кристалл-прародитель вышел "не маленьким" (вернее сказать, попросту гигантским); ведь совсем не секрет, что предком PowerPC970 служит процессор совершенно другого ценового диапазона, Power 4. Да-да, именно это ядро (после некоторого преобразования) было использовано для создания процессора для mainstream рынка. Собственно, сама по себе идея не лишена смысла: на момент появления процессор Power4 был одним из лидеров по производительности, да и сейчас выглядит более чем пристойно. Так для чего создавать себе лишнюю работу, изобретая новое ядро? Достаточно воспользоваться имеющимся интеллектуальным багажом, адаптировав его для нужд массового производства (сам по себе кристалл процессора Power4 имеет площадь 417мм2 – в массовом производстве такой монстр неприемлем в силу чрезвычайно высокой себестоимости). В результате проведенной работы имеем существенное снижение стоимости кристалла: процессорная сборка Power4 (включающая, правда, кэш третьего уровня) стоит в районе 10 000$. Сравните со стоимостью PowerPC970, составляющей сотни долларов. Оговоримся, что стоимость кристалла отдельно, без платформы, автору выяснить не удалось. Для подтверждения родства процессоров приведем иллюстрацию из презентации (авторства самой IBM):

Видно, что, пожертвовав вторым ядром, удалось сделать первое ядро более высокочастотным (в том числе благодаря переходу на более "тонкий" техпроцесс и удлинению конвейера), к которому также добавили SIMD набор инструкций. Впрочем, об этом наборе мы поговорим чуток позднее. Благо, поговорить есть о чем.
Пока же вернемся к нашему микропроцессору. Наступило время заглянуть "внутрь" микросхемы.
Куплет четвертый: и мы горды, и враг наш горд… Рука, забудь о лени…
Для начала займемся модулем, который есть в любом современном процессоре, вне зависимости от его "принадлежности" к той или иной архитектуре. Речь пойдет о модуле предсказания переходов (Branch Prediction Unit, BPU). Необходимость в таком модуле возникла из-за того, что в программах частенько встречаются те или иные условные переходы. Ну а теперь припомним, что в современных процессорах широко используется конвейеризация как средство нарастить частоту, попутно увеличивая процент одновременно используемых транзисторов (входящих в процессор). Другими словами, та или иная команда движется по конвейеру, по пути "обрастая" данными из памяти, результатами вычислений других инструкций, всевозможными дополнительными признаками и указателями. В результате каждый момент времени работает практически весь конвейер, обрабатывая на разных своих участках различные команды. Эта идиллия была бы полной, если бы не те самые злосчастные переходы. Наличие такого перехода (либо ожидание некоего условия) приводит к тому, что бесперебойная работа конвейера нарушается, снижая результирующую производительность микропроцессора. Выход из положения нашли в создании модуля, основной задачей которого является "угадывание" наиболее вероятного направления перехода.
Если попытка угадать была удачной, тогда мы будем вознаграждены бесперебойной работой конвейера с максимально возможной загрузкой. Если не угадаем – будем наказаны остановкой конвейера, очисткой всех буферов и загрузкой правильной ветки ветвления. Естественно, пенальти при неправильно угаданном переходе (в тактах процессора) может быть больше экономии тактов в правильно угаданном случае. Но спасает то, что правильно угаданных переходов намного больше – как правило, разработчики делают все, чтобы в большинстве реальных алгоритмов их детище смогло продемонстрировать как можно более близкий к 100% результат правильных предсказаний. В большинстве современных процессоров точность предсказаний близка или превосходит 90%. Поэтому в суммарном зачете этот способ все же выгоден, несмотря на то, что иногда результаты его работы приводят к необходимости очищать и заново заполнять конвейер. Зато, повысив точность предсказания, можно себе позволить увеличить длину конвейера, что весьма благотворно (при прочих равных условиях) сказывается на частоте процессора. Современные компиляторы в качестве резерва для повышения производительности частенько используют именно этот нюанс, располагая код таким образом, чтобы повысить точность предсказания переходов (благо, особенности работы соответствующих процессоров разработчикам компиляторов известны). Кстати, стоит отметить, что, по сравнению со своим прародителем Power4, в PowerPC970 длина конвейера заметно увеличилась: с 12 стадий до 16 (SIMD/FPU команды могут занимать до 25 стадий!). Как уже писалось выше, это еще один прием, позволивший заметно увеличить частоту PowerPC970 (снизив тем самым отставание по этому параметру, которое процессоры Mac-ов имели по сравнению с современными х86 процессорами).
Однако вернемся к модулю предсказания переходов. Для начала посмотрим, чем в этом плане могут похвастать флагманские модели от Intel и AMD. В процессоре Pentium 4 используется модуль истории переходов (branch history table, BHT) емкостью 4096 (4К) записей, алгоритм его работы основан на изучении предыстории ветвлений. Другими словами, накапливается статистика переходов, и преимущественным будет то направление, которое является наиболее вероятным согласно собранным статистическим данным.
В последнем микропроцессоре от AMD, Opteron-е (Athlon 64), реализован буфер размером 16К записей (!), то есть таблица истории переходов в четыре раза более емкая, чем в Pentium 4 (и в 4 же раза более емкая, нежели в процессоре Athlon XP). Благодаря этому удалось заметно повысить точность предсказания (насколько автору известно, она составляет более 95%). Тут у читателя, возможно, возникнет недоумение – что же это за "заметное повышение"? Было 90%, стало 95%... Где революция? Тут напомним, что 90% правильно угаданных переходов – это 10% ошибок предсказания. А 95% - соответственно, 5% ошибочно предсказанных переходов! Согласитесь, снижение количества ошибок вдвое уже подходит под словосочетание "заметно повышенная точность предсказания".
Посмотрим, чем могут похвастать прошлый и нынешний микропроцессоры Mac-ов. Начнем с G4+. Здесь все заметно скромнее: буфер истории переходов на 2К, а ВТВ на 128 записей. Правда, необходимо также отметить, что G4+ имеет конвейер длиной всего 7 стадий, соответственно, для него нет необходимости сооружать такой же мощный блок, как у современных процессоров, поскольку "пенальти" за неправильное предсказание намного меньше. А вот у PowerPC970 все заметно интереснее.
Прежде всего, сказалось родство с Hi End процессором Power4. Механизм предсказания у PowerPC970 достаточно сложный и, по-видимому, весьма эффективный – жаль только, что IBM так нигде [в открытой прессе] и не опубликовала оценок точности предсказаний. По крайней мере, автору их разыскать не удалось (впрочем, нельзя сказать, чтобы автор об этом сильно жалел). Прежде всего, PowerPC970 интересен тем, что использует сложную систему, основанную на двух постоянно работающих схемах предсказания переходов. Работающих одновременно.
Первая из них использует традиционный буфер истории переходов, имея предыдущие 16К записей переходов. Записи в этой таблице снабжаются соответствующими метками, означающими наличие/отсутствие перехода и правильность предсказания. На основе анализа этой информации и делается следующее предсказание.
Здесь сделаем отступление и поясним чуть подробнее – тем более, что в дальнейшем нам понадобится эта информация. Пройдемся по логике работы первой таблицы. В идеале, каждой инструкции перехода должен соответствовать 1-битовый элемент в таблице. Номер элемента можно получить по адресу инструкции – но так как размер таблицы ограничен, то доступ к элементу будет осуществляться не по всем битам 64-х (32-х) разрядного адреса, а только по некоторым. То есть, для таблицы размера 2^14 из адреса будут выделены 14 бит. Конечно же, может получиться так, что некоторым инструкциям перехода будет соответствовать один и тот же элемент, - однако это не так страшно: скорее всего, эти инструкции будут выполняться в разные, достаточно удаленные друг от друга промежутки времени, и, в сумме, "перенастройка" окажется незаметной. Т.к. размер элемента – 1 бит, то он может хранить лишь информацию о том, был ли в предыдущий раз совершен переход. Реально такой счетчик будет ошибаться дважды – когда, скажем, за 10 прохождений инструкции переход выполняется только один раз; если же переход должен совершаться каждый второй раз, то такой счетчик будет ошибаться всегда.
Вторая работающая схема использует таблицу такой же глубины, 16К. Но первая схема использует локальную таблицу переходов, а вот вторая – глобальную. Кроме того, каждая запись во второй таблице связана с 11-разрядным счетчиком (кстати, единым на весь процессор), который отмечает какой путь ветвления в результате был выбран в предыдущие 11 раз при выборке группы команд из L1 (блок загрузки загружает из L1-I по 8 инструкций), и насколько результативным было предсказание. Результаты обработки информации становятся основой для предсказания результатов следующего ветвления.
Теперь кратко опишем идею второй таблицы. Отвлечемся на время от предыдущей модели, и посмотрим, как будет выполняться некий произвольный участок нашего кода. Каждый раз, когда будет встречаться инструкция перехода, мы будем просто отмечать, что произошло: нужно было совершать переход, или нет. Т.е. нас пока не интересует адрес инструкции, а только результат. В конечном итоге мы получим последовательность из "да" и "нет". Попытаемся теперь предсказать следующий результат. Возьмем, например, 8 самых последних результатов. Понятно, что всего возможны 2^8=256 комбинаций, поэтому заведем специальный битовый массив из 256 элементов. Когда мы получим новый результат, запишем его в тот элемент массива, который будет соответствовать нашей истории. Например, если "история" выглядит так "да – нет – да – нет – нет – нет – нет – нет", и мы по ходу исполнения кода выяснили, что новый переход совершать не надо – нам следует занести 0 ("нет") в элемент массива с номером 5 (00000101 в двоичной системе). В следующий раз, когда встретится такая же "историческая комбинация" мы воспользуемся сделанной записью. Нетрудно дальше убедиться в том, что такая таблица будет очень неплохо настраиваться на короткие, но экзотические последовательности.
Мы увидели основное отличие этого метода от предыдущего; в первом варианте мы наблюдаем за отдельной инструкцией перехода, вне связи с остальными. Во втором же поступаем с точностью до наоборот: смотрим на последовательность результатов, не привязывая её к какой либо определенной инструкции. Собственно, именно это и подсказывают названия таблиц: локальная / глобальная.
И, наконец, некоторое усовершенствование: попытаемся расширить последнюю идею так, чтобы не "грести под одну гребёнку" все инструкции. Для этого нам достаточно будет увеличить размер таблицы, а для адресации к элементу использовать не сам "глобальный счетчик", а его комбинацию с, допустим, адресом текущий инструкции. Так, Athlon XP выбирает 4 бита адреса, добавляет к ним 8 битов счетчика (данные последних 8 переходов) и получает индекс элемента в global history bimodal counter table, GHBC. PowerPC970 использует 11 разрядный счетчик, комбинирует с битами адреса (используется не простое добавление, а логическая операция), и получает 14-ти разрядный индекс. Кстати, обрати внимание на ещё одно важное отличие: у Athlon XP (Athlon 64) размер элемента таблицы два бита, а не один, как у PowerPC970. Смысл в том, что используются не только две записи "да" или "нет", но и "возможно да" и "возможно нет"; при этом стратегия настройки оказывается более гибкой по сравнению с простыми однобитовыми элементами. Зато у PowerPC970 три таблицы!
Но главная изюминка данного модуля у PowerPC970 состоит в том, что существует третий (!) буфер на 16К, который занят анализом, какая же из двух схем оказалась более эффективной, то есть имеет меньше ошибочных предсказаний за некий промежуток времени. В результате процессор способен за относительно небольшое время скорректировать свои действия, выбрав тот алгоритм предсказаний, который более соответствует текущей обстановке! Жаль, что об этом весьма любопытном решении известно так мало – собственно, даже эта информация почерпнута отнюдь не из презентаций IBM, а из посторонних источников. Точнее сказать, информацию удалось почерпнуть из описания этого модуля у Power 4; похоже, что данный механизм PowerPC970 честно унаследовал от предка.
Резюмируем: похоже, что на сегодняшний момент времени среди современных процессоров PowerPC970 имеет один из наиболее совершенных модулей предсказания переходов. А ведь близится Power5, у которого этот блок наверняка будет подвергнут дополнительной доводке!
Куплет пятый: не вешать нос, гардемарины
Теперь приведем рисунок, иллюстрирующий устройство процессора:

Из этого рисунка уже можно сделать некоторое количество выводов: заметно, что у процессора два исполнительных конвейера, два FPU, есть модуль обработки SIMD инструкций, получивший название AltiVec. Но в глаза бросается кое-что другое. Стадия обработки команд, которая носит название "Decode"…. Позвольте, позвольте, какой такой Decode, почему Decode? Все время нас учили, что RISC – это как раз Reduced команды, то есть короткие и понятные для процессора. А тут процессор их во что-то превращает? Зачем это чудесные RISC инструкции во что-то превращаются? И как же тогда все это работает? Где логика?!
Логика на месте. Процессор PowerPC970 действительно превращает RISC команды в некоторую внутреннюю систему команд (жаль только, что неизвестно про нее практически ничего, кроме самого факта ее существования). Потому что PowerPC970 внутри использует набор инструкций, резко отличающийся от внешнего набора. Эта черта роднит его с процессорами х86, которые также преобразовывают внешние нерегулярные команды х86 переменной длины во внутренние команды (либо последовательности команд) одинаковой длины. Но то, что привычно видеть на х86, очень непривычно видеть на RISC процессорах, одной из ключевых особенностей которых всегда считалась именно система простых коротких команд. Благодаря этой простоте блоки исполнения команд сравнительно несложны, а большинство команд исполнялось аппаратно. Но одно дело, когда нам надо напрямую выполнять несколько десятков команд. И совсем другое дело, когда число поддерживаемых команд достигает двух сотен – ведь данный процессор поддерживает набор команд AltiVec, который включает ни много, ни мало, а 162 (!) инструкции. Так что такую меру следует признать вполне адекватной – проще добавить в процессор блок декодирования, нежели пытаться исполнять несколько сотен команд напрямую. К тому же дело не только в наборе AltiVec – просто IBM [и ее клиенты] накопили достаточно большое количество программного обеспечения, которое нельзя бросать, слишком уж много денег в него вложено. А на старом наборе команд не развернуться, стандартные методы повышения производительности процессоров практически исчерпаны. Вот и вышло, что похожие проблемы (необходимость сохранить инвестиции одновременно с необходимостью увеличить производительность) привели к похожим на х86 процессоры методам решения: внедрению блока декодирования.
Ну а история в очередной раз доказала, что она дама с юмором. Система команд х86, а затем система декодеров (называемая не иначе как "костыли для х86") не единожды была мишенью для насмешек со стороны "апологетов" RISC. Собственно, превращение х86-команд в RISC-подобные внутри процессора всегда рассматривалось как победа дела RISC. Дескать, понятно, что настоящие процессоры не нуждаются в преобразовании команд в "удобоваримую" для процессора форму. А вот "неправильные" процессоры вынуждены переводить свою внешнюю систему команд во внутреннюю, "правильную", RISC подобную. Интересно, что они скажут теперь? :)
Само разложение происходит способом, чем-то похожим на способ работы декодера Athlon. Все команды делятся на две группы. Первая из них, группа cracked instructions, состоит из команд, которые распадаются на две простейшие операции (IBM называет их IOPs). Вторая группа, millicoded instructions, распадается более чем на две IOPs. Каждый такт микропроцессор PowerPC970 в состоянии направить в исполнительные блоки группу из пяти IOPs. Подавляющее большинство микроопераций заполняют в группе места с нулевого по третий "слоты". А слот 4, соответственно, всегда зарезервирован для branch prediction операций (операций предсказания перехода). Если нет операций, которые бы могли заполнить предыдущие слоты, или их количество недостаточно, декодер вставляет так называемые NOPы, (no op, сокращение от no operation). Другими словами, NOP – это команда "не делать ничего".
Кроме того, есть еще некоторые ограничения, связанные с местами микроопераций внутри группы. После того, как Cracked instruction превратится в два IOP-а, оба этих IOP-а должны находиться внутри одной группы. Если так не получается, декодер вставляет NOP и начинает новую группу. Инструкции, которые являются millicoded instructions, всегда начинаются с новой группы. Если какая-то инструкция вызывает millicoded instruction, она также начинается с новой группы.
Вот эти нюансы (и ограничения) очень напоминают те нюансы и ограничения, которые существуют в декодере процессора Athlon XP. В процессоре Athlon 64, как мы знаем, декодер был значительным образом переработан и улучшен. Посему данный блок мы будем считать приличным, но не выдающимся; нам известны несколько более эффективная реализация декодера.
Кроме этого [в высшей степени необычного] для RISC процессоров блока декодирования, в PowerPC970 увеличилась емкость всех буферов по ходу конвейеров (кстати сказать, основная работа на стадиях декодирования – не только (и не столько) переработка cracked-инструкций, но и разрешение зависимостей, плюс формирование группы микроопераций). И теперь IBM (а вслед за ней и Apple) с гордостью говорят о том, что в процессоре PowerPC970 на разных стадиях обработки могут находиться 215 инструкций. Это, по словам Apple, заметно больше, чем у Pentium 4, у которых ширина этого "окна" составляет 126 инструкций. И более чем на порядок превосходит ширину "окна" процессора G4+, у которого она составляет 16 команд. Чуть ниже мы укажем на тот факт, что на самом деле PowerPC970 не имеет такого большого преимущества; суммарное количество "инструкций на лету", похоже, весьма близко у PowerPC970, Athlon 64, и Pentium 4. Остановимся чуть подробнее на одном моменте.
Практически половина таких инструкций (IOP) находится в буфере Group Completion Table. Собственно, это функциональный аналог блока переупорядочивания инструкций (Reorder Buffer) – там может храниться до 20 сформированных групп микроинструкций (то есть порядка 100 IOP-ов), которые и направляются затем в очереди на исполнение. Заметим, все это происходит в порядке, оговоренном кодом программы. Из очередей же микроинструкции по мере готовности направляются на исполнительные устройства, без сохранения порядка следования в программе. "Внеочередное исполнение команд" появляется именно в этом месте! Как только ФУ "подтвердило", что операция проводится успешно, место в очереди освобождается. Заметим, что
это может происходить до того, как микроинструкция будет выполнена функциональным устройством (ФУ);
Group Completion Table продолжает следить за ее дальнейшей судьбой.
Когда выполнена вся группа микроинструкций, и выполнены все предыдущие группы, процессор произведет запись окончательных результатов, и место в Group Completion Table будет освобождено. Кроме того, если буфер Group Completion Table полон, то декодер не производит декодирование команд и создание следующих групп до тех пор, пока не появится свободное место. Понятно, что для оценки возможностей данного процессора нам следует использовать минимум два параметра: размер Group Completion Table и размер очередей. Еще раз уточним их смысл: размер Group Completion Table, грубо говоря, показывает максимальную величину непрерывного блока инструкций (как-бы вырезанного из программы), который может обрабатываться процессором в какой-либо момент времени. Точнее сказать, это есть максимальное количество обрабатываемых микроинструкций, в которые превращаются команды из непрерывного куска программы. Глубина очередей: максимальное количество микроинструкций, из которого производится out-of-order – выборка. Естественно, мы для простоты в данном случае подразумеваем тождественность "инструкции программы" и микрооперации. Также мы должны учитывать и другие особенности микроархитектуры: так, очевидно, что в случае длинного конвейера объем Group Completion Table должен быть увеличен, потому что время обработки отдельных инструкций становится большим.
Здесь сделаем небольшое отступление: дело в том, что здесь мы имеем дело с очередными "маркетинговыми изысками". Цифра "126 инструкций на лету", которую приводит Apple по отношению к процессору Pentium 4, относится не ко всему конвейеру, а только к блоку Reorder Buffer. Цитируем: "The Allocator allocates a Reorder Buffer (ROB) entry, which tracks the completion status of one of the 126 uops that could be in flight simultaneously in the machine". Соответственно, корректнее будет сравнивать "ширину" этого "окна" с буфером Group Completion Table в процессоре PowerPC970.
Для процессора Athlon 64 необходимо сделать такое же уточнение, и сравнивать с reorder buffer, размер которого составляет 72 макрооперации (The reorder buffer allows the instruction control unit to track and monitor up to 72 in-flight macro-ops (whether integer or floating-point) for maximum instruction throughput). Заметим также, что цифра относится именно к макрооперациям – соответственно, для микроопераций это число в идеале приближается к 144 микрооперациям, хотя в реальной жизни, безусловно, ближе к первой цифре. Сравним с приблизительно сотней инструкций в блоке Group Completion Table. Похоже, что в плане количества одновременно обрабатываемых "инструкций на лету" никаких выдающихся отличий у процессора PowerPC970 обнаружить не удается. Вопреки заявлениям Apple.
Достаточно много места необходимо для процедуры "переименования регистров". Как известно, эта процедура необходима для того, чтобы можно было выполнять одновременно несколько команд, обращающихся к одному и тому же регистру. В результате каждой из команд "подсовывают" регистр с нужным названием, ну а какому реальному физическому регистру он соответствует, это уж дело десятое. Собственно, сама процедура переименования регистров выполняется практически всеми современными процессорами. Кроме того, надо отметить, что суммарное количество внутренних "регистров переименования" должно быть пропорционально суммарному количеству обрабатываемых инструкций. Сравним PowerPC970 с упомянутыми ранее процессорами.
Проще всего процессор G4+. Он оперирует 32 архитектурными регистрами, и 16 "регистрами переименования", всего 48 штук.
Процессор PowerPC970 оперирует 80 регистрами, то есть 32 архитектурными и 48 "регистрами переименования".
Процессор Athlon 64, если автору не изменяет память, имеет 8 (16 в режиме AMD64) архитектурных регистров, и, в общей сложности, порядка сотни внутренних регистров.
Процессор Pentium 4 оперирует 8 архитектурными, и 120 (!) "регистрами переименования". Что ж, внушает!
Но все они блекнут по сравнению с процессором Itanium: 320 регистров. Подчеркнем, архитектурных регистров!
Здесь опять сделаем отступление, и поясним, что деление регистров на "архитектурные" и "регистры переименования" несколько условно. Понятно, что мы имеем дело с неким набором физических регистров, на которые динамически отображаются (ставятся в соответствие) архитектурные регистры. Также понятно, что выгодно иметь как можно больше физических регистров. Но увеличение их количества связано со значительными трудностями: это, фактически, наиболее "горячая" часть процессора (в том плане, что блоку переименования регистров работа найдется всегда). Кроме того, чем больше регистров, тем труднее проводить из них выборку. А размеры таковой выборки определяются в том числе и количеством архитектурных регистров. Таким образом, большой набор регистров, кроме достоинств, имеет и вполне определенные недостатки.
Видно, что в этом виде "состязаний" PowerPC970 ничего выдающегося не демонстрирует; но и отстающим он не является, вполне приличный процессор. Тем более, что число физических регистров для переименования было значительно увеличено по сравнению с предшественником, G4+ – хотя бы для того, чтобы соответствующим образом поддержать заметно увеличившееся количество "инструкций на лету". Понятно ведь, что чем больше инструкций нам надо исполнять "на лету", тем больше физических регистров нам понадобится. Отметим также, что, говоря о регистрах, мы имели в виду именно general register, не включая другие. Иначе у нас получились бы совсем другие числа: в частности, для PowerPC970 можно привести такую таблицу (источник):
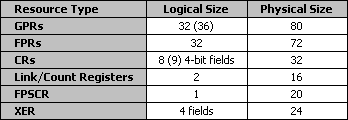
Таким образом, на самом деле общее число регистров для PowerPC970 составляет 244! Правда, для полноты картины надо указать, что и у других процессоров общее число регистров заметно выше – как правило, большинство материалов по этому поводу оперирует только количеством general purpose регистров.
Куплет шестой: пятнадцать человек на сундук мертвеца…
Но продолжим про внутреннее строение процессора. На этот раз присмотримся к его исполнительным модулям. Здесь тоже все не так просто, как может показаться. PowerPC970 имеет два целочисленных исполнительных устройства (IU), каждое из которых спарено с блоком загрузки (Load/Store). По числу устройств нельзя сказать, чтобы мы увидели что-то особо выдающееся: у Pentium 4 есть два быстрых ALU, работающих с удвоенной частотой (не считая "медленного" ALU для некоторых видов операций). У G4+, правда, их также два: одно исполнительное устройство используется для простых операций (сложение), другое для более сложных (целочисленное деление). У Athlon 64 так и вовсе три ALU. Но IBM бы не была IBM, если не подкинула нюансов в архитектуру. Эти два исполнительных устройства (IU) в PowerPC970 не совсем одинаковы. Простые операции – сложение, вычитание – производятся совершенно одинаково обоими блоками. А вот на уровне более сложных операций есть своя "специализация": например, все деления в процессоре PowerPC970 выполняет IU2. Сама IBM называет эти блоки "слегка разными", что еще больше запутывает ситуацию. К сожалению, нам не удалось выяснить, кто именно отбирает команды в соответствии с их спецификой, и направляет на соответствующее исполнительное устройство (IU). Кроме того, не слишком ясно, что же произойдет, если, например, в группе IOP-ов будет несколько команд деления. Станут ли они все дожидаться IU2? Если да, то в этот момент мы и получим "узкое место" этой архитектуры. Или, возможно, декодер следит за тем, чтобы группы были по возможности сбалансированы? В общем-то, наиболее вероятен второй вариант, весь вопрос только в том, насколько велики возможности декодера по перестановке IOP-ов местами. Впрочем, отметим, что, по сравнению с Pentium 4 или Athlon XP, PowerPC970 заметно более "симметричен" - деление все же достаточно особая операция, сравнимая разве что со "стихийным бедствием".
К сожалению, IBM практически не публикует информацию о задержках (Latency) и темпе запуска (Throughput) инструкций в PowerPC970. Известно, что часть простых инструкций исполняется за один такт (исключая, естественно, декодер), остальные обрабатываются несколько тактов. Независимые IOP-ы могут стартовать каждый такт, зависимые друг от друга – не быстрее каждого второго такта. Кое-что можно попробовать оценить по приведенной схеме стадий конвейера: так, например, наиболее вероятной латентностью доступа к данным, находящимся в L1 cache, будут 4 такта.
Теперь перейдем к блокам загрузки/выгрузки (Loasd/Store). В этих блоках имеется некоторое отличие от идеологии, принятой в х86 процессорах (Pentium 4, Athlon 64). В х86 процессорах существует два блока для обработки целочисленных и вещественных загрузок/выгрузок. Например, согласно известному сайту arstechnika.com, в Pentium 4 существует следующая специализация:
Все LOAD: LSU (Load/Store Unit);
Целочисленные STORE: LSU;
Вещественные STORE: FSTORE;
Vector STORE: FSTORE.
Автор затрудняется высказаться по этому поводу: есть некоторые сомнения в правильности такого "разделения обязанностей", которые, однако, трудно подтвердить или опровергнуть. А вот в PowerPC970 эти блоки идентичны, то есть абсолютно всеми типами загрузки/сохранения "заведуют" специальные блоки, каковых два. Правда, остается весьма неясным момент с векторными операциями – в родоначальнике семейства, процессоре Power 4, нет блока операций с векторами. Соответственно, не очень понятно, сколько и каких векторных операций Load/Store может производить соответствующий блок в PowerPC970. Возможно, что также есть некоторая специализация, и один блок заведует Vector LOAD, а другой – Vector STORE, но это всего лишь предположение. Возможен и другой вариант – блоки выполняют только Vector LOAD, а Vector STORE совмещен с исполнительными устройствами конвейера. Впрочем, все может оказаться еще хуже, и всеми операциями с векторами может ведать только один блок.
Теперь перейдем к FPU. Для начала напомним, что у PowerPC970 есть два полностью идентичных блока FPU, каждый из которых может выполнить любую операцию с вещественными числами. При этом наиболее быстрая операция может быть выполнена за 6 тактов, наиболее медленная за 25 тактов. Оба блока полностью конвейеризированы, то есть каждый такт на исполнение может быть отправлена следующая команда [вслед за предыдущей] (если, конечно, они не зависят друг от друга). Также напомним, что PowerPC970 имеет в целом 72 физических FPU регистра. Из них 32 архитектурных регистра, а 40 – "регистры переименования". Кроме того, есть еще несколько приятных особенностей. В частности, PowerPC970 поддерживает очень полезную комбинированную инструкцию – умножение + сложение "в одном флаконе". Так как она может запускаться на каждом из двух FP-блоков каждый такт, получается, что за один такт будут выполнены 4 "операции". Существенным это может оказаться, в частности, при перемножении матриц, и во многих других задачах линейной алгебры.
Кроме всего прочего, на PowerPC970, очевидно, возможен одновременный запуск двух операций сложения (или двух операций умножения) – что нельзя сделать, например, на Athlon XP в силу несимметричности двух FPU блоков последнего (один на сложение, другой на умножение). То же справедливо и для Pentium 4, где ситуация еще хуже, так как в x87-режиме лимитирующим фактором окажется пропускная способность портов (1 операция за такт).
Безусловно, увеличившаяся вычислительная способность процессора потребовала дополнительной полосы пропускания от памяти и процессорной шины, каковые и были ему предоставлены: чуть ниже мы рассмотрим, что интересного в PowerPC970 с этой точки зрения.
Ну а сейчас займемся еще одним блоком процессора PowerPC970: блоком AltiVec. Здесь необходимо сделать некоторое отступление, и привести схематическое устройство этого блока у процессора G4+.

иллюстрации взяты с сайта arstechnika.com
Мы видим, что блок включает в себя:
Vector Permute Unit;
Vector Simple Integer Unit;
Vector Complex Integer Unit;
Vector Floating-point Unit.
При этом данный блок пользуется 32 регистрами длиной 128 бит. Еще 16 "регистров переименования" дополняют этот блок, способствуя работе внеочередного исполнения команд (out-of-order). Производительность данного блока такова: каждый цикл процессор G4+ может исполнить два векторных IOP-а за такт в любых трех блоках из четырех.
Устройство данного блока у процессора PowerPC970 слегка отличается. Приведем картинку:

иллюстрации взяты с сайта arstechnika.com
Как видно, организация блока AltiVec (кстати говоря, сама IBM называет его по-другому, но автор умышленно применяет "неродной" для IBM термин, дабы избежать путаницы) несколько другая. Есть два различных блока: Vector Permute Unit; Vector Arithmetic Logic Unit. Последний, в свою очередь, состоит из:
Vector Simple Integer Unit;
Vector Complex Integer Unit;
Vector Floating-point Unit.
Из-за такого устройства блока AltiVec появляются некоторые ограничения, которых не было в процессоре G4+. Процессор PowerPC970 может исполнять за такт те же два векторных IOP-а, но при одном условии: один из этих IOP-ов должен быть предназначен для Vector Permute Unit. Второй для любого из трех оставшихся конвейеров блока Vector Arithmetic Logic Unit. Естественно, что дополнительные ограничения вряд ли улучшат производительность блока. Ну и, естественно, кроме архитектурных 32 регистров, у процессора PowerPC970 есть некоторое количество "регистров переименования". Предположительно, общее число физических регистров в блоке AltiVec – порядка 72 или 80 штук.
По всей видимости, IBM была вынуждена изменить конструкцию этого блока для того, чтобы поднять рабочие частоты процессора. Впрочем, это лишь предположение автора, однако постараемся его подтвердить. В пользу такого предположения говорит следующая таблица, где указаны глубина конвейера (в стадиях) нескольких типов команд:

Можно резюмировать, что данный блок подвергся некоторой ревизии, которая, без сомнения, немного снизила производительность за такт, но позволила заметно поднять рабочие частоты.
Куплет седьмой: подайте мне доспехи, седлайте мне коня!
Ну, вот мы и добрались до процессорной шины и подсистемы памяти в PowerPC970. Здесь ситуация на сегодняшний момент достаточно привлекательна: шина процессора PowerPC970 работает на одной четверти частоты процессора (то есть для процессора 1.8ГГц это составляет 450МГц). При этом шина использует технологию DDR, и эффективная пропускная способность соответствует таковой для шины частотой 900МГц. Что при ширине 64бита (здесь есть нюансы, о которых ниже) составляет теоретически 7.2Гбайт/секунду. При этом IBM приводит в качестве оценки средневзвешенной пропускной способности цифру 6.4Гбайт/секунду. По мысли IBM, это более реальная оценка, учитывающая задержки (latency) выборки из памяти и некоторые особенности работы чипсета. То есть, на сегодняшний момент у PowerPC970 самая быстрая шина среди всех процессорных архитектур. Однако на самом деле шина PowerPC970 состоит из двух однонаправленных (!) шин шириной по 32 бита. То есть, на самом деле можно рассчитывать на 3.6Гбайт/секунду в каждую сторону, но не на 7.2 в одну (кстати, нельзя не заметить сходства с "системной шиной" Hyper Transport процессора Athlon 64). Еще один нюанс состоит в том, что шина Rapid I/O* имеет интересное свойство (по крайней мере, в теории): она может менять свое направление. За достаточно небольшое время (несколько сотен процессорных тактов) контроллер шины в чипсете может переключить ее в однонаправленный режим, в котором шина начинает работать в одну сторону. К сожалению, нам неизвестно, реализован ли данный режим в чипсете новой платформы Apple. А было бы очень интересно попытаться проверить результативность этой идеи. Равно как и интересно, часто ли потоки данных в процессор и из процессора настолько отличаются, чтобы имело смысл так делать…
* - (так IBM окрестила все семейство своих высокоскоростных последовательных шин; правда, вот здесь она называется Elastic I/O).
Претерпела изменения и подсистема памяти – вместо DDR SDRAM, работающей на 166МГц (DDR333), платформа PowerPC970 использует двухканальную память DDR SDRAM стандарта DDR400. Что ж, заметная разница, не так ли? 6.4Гбайт/секунду вместо 2.7Гбайт/секунду. Отметим, что в реальной ситуации пропускную способность DDR SDRAM на платформе G4+ востребовать не удавалось по причине того, что процессорная шина пропускает только 1.3Гбайт/секунду (похожая ситуация была с платформами Pentium 3 и памятью DDR SDRAM – никакого заметного эффекта применение памяти DDR не давало). Собственно, именно подсистеме памяти (а еще ускорившейся шине) платформа PowerPC970 во многом обязана увеличившейся производительности – предыдущая платформа, G4+, использовала шину с частотой 166МГц (синхронно с памятью). Соответственно, пропускная способность памяти выросла более чем в два раза, а шины – так и вовсе практически в пять раз.
Помимо всего прочего, процессор PowerPC970 поддерживает SMP режим (режим симметричной многопроцессорности). Посему для построения двухпроцессорных систем не нужно ничего особого. Кстати, возможность PowerPC970 работать в многопроцессорных системах активно используется Apple в рекламной компании, посвященной системам на базе данного процессора. Интересно, что, невзирая на сходство шин Elastic I/O и Hyper Transport, для построения двухпроцессорной системы используется шинная архитектура, примерно как в системах у Intel. Забавное решение, хотя, в общем-то, понятное – шинная архитектура обычно несколько проще в реализации. К тому же для построения десктопов и недорогих рабочих станций ее достаточно, тогда как вариант NUMA потребовал бы более серьезной проработки операционной системы. А это достаточно "больная" тема – и без того, как уже указывалось выше, процесс перехода проходит совсем не так гладко, как хотелось бы Apple.
В целом, на данном "фронте" у PowerPC970 все в полном порядке.
Куплет восьмой: ничего на свете лучше нету
Ну что ж, окинув взглядом все предыдущие абзацы, можно сказать, что процессор PowerPC970 выглядит вполне удачным. Кое в чем он попросту лидер, кое в чем – весьма "на уровне". Но практически нет ни единой области, где процессор явно и сильно проигрывал бы чипам-конкурентам. Соответственно, и производительность от этого процессора можно ожидать достаточно высокой – по крайней мере, на уровне современных лидеров. Чуть позже мы посмотрим, что именно продемонстрировали системы на базе PowerPC970.
Пока же хочется сделать небольшое лирическое отступление: несмотря на все великолепные и потенциально выигрышные черты любой архитектуры, с ней (архитектурой) необходимо сделать еще одну очень важную вещь. Ее надо кому-то продать. Именно поэтому частенько сроки выпуска того или иного продукта определяют не инженеры, а работники маркетинговых отделов. Тем читателям, которые хотели бы верить в первоочередность именно инженерной составляющей, автор напомнит один, но очень красноречивый пример – DEC. Эта корпорация, являясь разработчиком и изобретателем очень многих эффективных технических решений, допустила один роковой просчет. Она не обращала особого внимания на технологии продажи своих решений – на тот момент, без сомнения, лучших в мире. Обратим внимание, лучших с технической точки зрения! Итог был печальным, но закономерным. Разработчик одного из самых быстрых микропроцессоров того времени (кстати, легендарного первого 64 битного микропроцессора Alpha) фактически разорился, и был куплен фирмой Compaq (забавно, но и она вскоре была поглощена фирмой НР). Разработчик, который долго служил примером того, как надо строить высокопроизводительные системы, оказался "не у дел" по одной простой причине: он уделял мало внимания маркетингу, ошибочно считая, что, дескать, хорошая вещь и сама по себе будет продаваться. Увы, это не так. Большинство покупателей не являются специалистами в компьютерах – они являются специалистами совсем в других областях. Соответственно, нужен кто-то, кто растолкует им, почему им нужно покупать именно этот продукт. Именно такая работа является главной для маркетингового отдела любой фирмы.
Без сомнения, эти азбучные истины о необходимости маркетинга известны и Apple. К тому же именно в Apple маркетинг традиционно силен – думаю, любой читатель без труда припомнит несколько гениальных находок Apple. Поэтому вполне естественно, что новые микропроцессоры тут же оказались в фокусе маркетинговых разработок. И вот тут произошло одно малозаметное, но крайне неприятное в плане последствий явление.
Одним из наиболее сложных нюансов в любой рекламе собственного продукта является его сравнение с потенциальными конкурентами. Свой продукт нужно похвалить, это понятно. Понятно также, что при этом необходимо соблюдать максимальную корректность, или хотя бы ее видимость. Любое принижение достоинств конкурирующего продукта воспринимается крайне негативно, такова уж особенность людей. Вам верят до тех пор, пока не поймают на лжи. Соответственно, лгать напрямую маркетинговый отдел не имеет права, последствия для имиджа фирмы будут катастрофическими. В этих предложениях нет ничего, что могло бы претендовать на открытие, это давно известные вещи.
В связи с вышесказанным документ авторства Apple оставил у автора чувство оторопи. Даже ожидая некоторое количество "преувеличений", которые обычно встречаются в рекламных материалах, автор был шокирован той дезинформацией, которая подавалась (и подается) в официальном документе Apple, посвященном выпуску новых систем. Нет, автора не смущают эпитеты "самая быстрая система", "оставляет далеко позади", и тому подобные словеса – маркетинг есть маркетинг. Но чуть ниже представители Apple устроили пародию на объективность, приведя показатели производительности в кросс - платформенном тесте SPEC CPU 2000. Для начала присмотримся к лидерам современного парада производительности. Вот табличка, которая представляет показатели производительности в этом тесте (выбран результат Base). Обращаем внимание, что это данные, приведенные на официальном сайте SPEC. Чуть позже станет понятно, почему автор концентрировал на этом внимание. Итак:

* – предварительная оценка IBM.
Итак, теперь некоторые комментарии к таблице.
Прежде всего, бросается в глаза, что показатели PowerPC970 наиболее низкие среди конкурентов (сразу оговоримся, что процессор Power 4+ принадлежит совсем другому целевому рынку; просто было интересно взглянуть, насколько потомок отличается от предка). Даже то, что приведенные оценки относятся к 1.8GHz процессору, а уже доступен 2.0GHz, не сглаживает тот факт, что процессор PowerPC970 все же ощутимо медленней остальных участников. Хочется отметить, что выпуск "экстремальных версий" как Pentium 4, так и Athlon 64 привел к тому, что х86 процессоры сделали сильный рывок вперед, и теперь вне досягаемости для PowerPC970.
Видно, что PowerPC970 сильно отстает от Power 4+ именно в FPU (впрочем, его FPU по сравнению с родоначальником был сильно урезан). Хуже совсем другое: он сильно (от 20% до 33%) отстает от конкурентов из х86 мира. Соответственно, рассчитывать на то, что процессор в серьезных научных расчетах сможет конкурировать с х86 процессорами, не стоит – в лучшем случае, будет не слишком отставать. При условии, разумеется, что программное обеспечение должным образом оптимизировано под все платформы.
С другой стороны, даже такой вот PowerPC970 – весьма немалое подспорье для Apple, которая уже давно не давала никаких внятных показателей производительности. Не считать же, в самом деле, результатами некие "тесты" в Photoshop без какой-либо внятной методики. Просто столбики результатов. Так что можно надеяться, что с этим процессором платформа Mac-ов сильно сократит отставание в производительности от х86 платформ, которое сложилось на сегодняшний момент.
Естественно, автор искал результаты испытаний PowerPC970 от Apple. И, когда Apple опубликовала свои "результаты", попросту не поверил своим глазам. А затем нашему возмущению не было предела. Безусловно, свою платформу хочется выставить в более выгодном свете. В этом нет ничего страшного – так делают все. Однако, когда в процессе рекламы своей продукции фирма идет на прямой подлог, и специально снижает результаты конкурентов, это производит крайне гнетущее впечатление! Посудите сами, что можно сказать о таких вот "результатах" измерений (в документе Apple используются результаты Pentium 3.0GHz):

Что и как (!) нужно мерить, чтобы "умудриться" снизить результаты вдвое? Напомним, что главная идея тестов SPEC состоит в достижении максимальной производительности для исследуемой платформы. В выборе компиляторов участники не ограничены. Нам трудно объяснить подобное расхождение чем либо, кроме крайней нечистоплотности маркетингового отдела Apple – даже применение других компиляторов обычно не способно снизить производительность процессора вдвое (!) в SPECfp_base 2000. При этом Apple выбирает не самый быстрый компилятор для Pentium 4, с которым сравнивает свои системы. Да еще и не применяет набор инструкций SSE2, мотивируя это тем, что повышения производительности при применении этого набора Apple не получила (!). Мда…. Весь мир получает, а Apple нет…. Может, тогда "в консерватории" что-то подправить?!
Более того, самое обидное, что даже такой "дешевый" способ побеждать не принес Apple ничего радостного – показатели производительности самого PowerPC970, отснятые Apple, равны для SPECint_base 2000 800, а для SPECfp_base 2000 всего 840. Учитывая, что Apple тестировала PPC970 частотой 2ГГц, совершенно необъяснимо, как они умудрились проиграть результатам IBM для процессора с частотой 1.8ГГц (напомним, IBM приводит цифры 937 и 1051 соответственно). Совершенно бесталанная поделка, если называть вещи своими именами – не думаю, что подобные методы "тестирования" прибавят Apple популярности. Неужели все настолько плохо с продажами, что необходимо прибегать к подлогу?!
Но, может быть, все дело в том, что пока никак не используется козырная карта процессоров PowerPC970 – технология AltiVec? Может быть, применение этой технологии чудесным образом все изменит?
Если бы…. Здесь мы опять наблюдаем маркетинговые "чудеса". Во-первых, Apple тщательно оперирует некими мифическими 16 Gigaflops на частоте 2GHz. При этом "забывая" самую мелочь: указать, что эти цифры относятся к 32 битной (!) точности расчетов. При этом позволим себе напомнить, что понятие Gigaflop, вообще говоря, определено для 64 битной точности расчетов. Да, можно придумать области применения, где и 32 битной точности представления числа достаточно для расчетов. Но таких расчетов далеко не так много – в основной своей массе для научных или технических расчетов используется 64 битное представление. Как представление, обеспечивающее минимально-достаточную точность. Делать вид, что 32 бит точности достаточно всем – не просто преувеличение, а преднамеренная ложь. Ведь это не так. Естественно, эта "производительность" без зазрения совести сравниваются с корректными цифрами производительности для х86 процессоров. При 64 битной точности. Все это, к тому же, подается под соусом "честного сравнения"….
Простите, господа "маркетологи" из Apple, но жевать эту "бурду" не хочется. Либо соответствуйте стандартным условиям тестирования комитета SPEC (или отдавайте тестировать системы на сторону), либо не приводите цифры производительности в SPEC. Вовсе. То есть вообще не публикуйте результаты измерений, если уж без откровенной лжи не обойтись. Рассказывайте о неимоверной легкости использования, об удобстве для пользователя, про катастрофическую устойчивость системы. Про легкость освоения, в конце концов, и про лидерство в мультимедиа. Потому что иначе от всего этого "маркетинга" сильно попахивает лицемерием и проигрышем. Вернее сказать, это и есть лицемерие и проигрыш. В погоне за маркетингом Вы позабыли главное: маркетинг должен демонстрировать преимущества, а не вводить в заблуждение. Ваш "маркетинг" попросту откровенная ложь.
Вы не справились, господа. А жаль. Право слово, Вам достался не худший из процессоров.
Эпилог
На этой грустной ноте позвольте автору закончить эту статью. Перед нами пример, когда неуемное рвение маркетингового отдела привело к совершенно недостойным результатам. И на сегодня можно сделать следующий вывод: да, процессор (и платформа) PowerPC970 неплохи. Не более того. Да, отставание от х86 процессоров есть. И на сегодняшний момент не видно никаких предпосылок к тому, чтобы это отставание исчезло. И никакие кластеры на базе PowerPC970 не изменят ситуации (недавно Apple с триумфом объявила о создании кластера на базе двухпроцессорных платформ PowerPC970 в одном из американских университетов). Кстати, не преминем отметить, что и здесь Apple попросту "лукавит" (читай: лжет), называя в качестве цены кластерной системы 5 миллионов долларов. Эта цифра не включает стоимости создания кластера (студенты, создававшие его, работали за пиццу!), стоимости системы охлаждения, и ряда дополнительных затрат. И, как стыдливо признается сама Apple, для этого кластера университету была предоставлена специальная (!) цена на оборудование. Ну а про то, сколько места занимает эта система, автор промолчит: использовались обычные (!) корпуса, а не Rack Mount (стоечное) исполнение.
Автор надеется, что такие "приемы маркетинга" не станут обычным делом для фирмы Apple. Слишком уж грустно глядеть, как занимается профанацией фирма, стоящая у истоков многих коренных изменений в персональных компьютерах.
P.S. Ну а закончить всю эту историю позвольте Киплингом – отрывком из его бессмертной "Заповеди":
[…]
Владей собой среди толпы смятенной,
Себя клянущий за смятенье всех,
Верь сам в себя, наперекор вселенной,
И маловерным отпусти их грех;
Пусть час не пробил, жди не уставая,
Пусть лгут лжецы, не снисходи до них;
Умей прощать и не кажись, прощая,
Великодушней и мудрей других..
[…]
Автор должен высказать свою огромную благодарность Вадиму Левченко (Vlev), Юрию Маличу (Yury_Malich), Сергею Романову (GReY), и Филимоновой Валерии (Lerka), чьи отзывы помогли в создании этой статьи. Особая благодарность Яну Керученько (C@t), консультации которого служили основой при формулировке наиболее сложных мест.
Библиография
1. PowerPC 970: First in a new family of 64-bit high performance PowerPC processors
2. IBM TRIMS POWER4, ADDS ALTI VEC
3. PowerPC Microprocessor Family: Programming Environments Manual for 64 and 32-Bit Microprocessors
4. PowerPC G5 White Paper December 2003
5. Power Mac G5Technology and Performance Overview November 2003
6. Inside the IBM PowerPC 970. Part I: Design Philosophy and Front End
7. Inside the IBM PowerPC 970. Part II: The Execution Core
8. SPEC CINT2000 Results Published by SPEC
9. SPEC CFP2000 Results Published by SPEC



© 1998-2023 fcenter.ru | Россия
© 1998-2023 fcenter.ru | Россия