Ваш город: Москва
ATI RADEON X800 XT Platinum Edition и RADEON X800 PRO. Вторая часть.
Вступление: И вновь продолжается бой...
RADEON X800 – новая линейка графических карт
Энергопотребление – хорошие новости от ATI
ATI R420: 8, 12 или 16 конвейеров?
ATI RADEON X800 XT Platinum Edition и RADEON X800 PRO: под пристальным взглядом
Третья часть:
Анизотропная фильтрация
Анизотропная фильтрация: производительность
Полноэкранное сглаживание
Полноэкранное сглаживание: производительность
Полноэкранное сглаживание: Temporal Antialiasing
Четвертая часть:
Драйверы, настройки и конфигурация тестового стенда
Синтетические тесты: cкорость заполнения
Синтетические тесты: пиксельные шейдеры
Синтетические тесты: вершинные процессоры
Синтетические тесты: TnL, спрайты, EMBM и т.д.
Выводы по результатам синтетических тестов
Пятая часть:
Игровые тесты: RTCW: Enemy Territory
Игровые тесты: Call of Duty
Игровые тесты: Unreal Tournament 2003
Игровые тесты: Unreal Tournament 2004 Demo
Игровые тесты: Halo: Combat Evolved
Игровые тесты: Tron 2.0
Игровые тесты: FarCry
Игровые тесты: Firestarter
Игровые тесты: Painkiller
Игровые тесты: Tom Clancy’s Splinter Cell: Pandora Tomorrow
Игровые тесты: Tomb Raider: Angel of Darkness
Игровые тесты: Prince of Persia: Sands of Time
Игровые тесты: Max Payne 2: The Fall of Max Payne
Игровые тесты: Star Wars: Knights of The Old Repubilc
Игровые тесты: IL-2 Sturmovik: Forgotten Battles
Игровые тесты: Lock On
Игровые тесты: X2: The Treat
Игровые тесты: F1 Challenge 99-2002
Игровые тесты: Colin McRae Rally 04
Игровые тесты: C&C Generals: Zero Hour
Полусинтетические тесты: Final Fantasy XI Official Benchmark 2
Полусинтетические тесты: Aquamark3
Полусинтетические тесты: Futuremark 3DMark03 build 340
Заключение
High Definition Gaming или возможности и особенности ATI RADEON X800
С объявлением новой архитектуры X800 (R420) и новой серии графических процессоров, RADEON X800 XT и RADEON X800 PRO, компания ATI вводит в обиход новую концепцию: High Definition Gaming.
Своим появлением концепция HD Gaming обязана рапространению HDTV - телевидения высокой четкости - и устройств отображения, поддерживающих стандарт HDTV.
Качество изображения в стандарте HDTV трудно сравнивать с обычным изображением: это не просто более высокое разрешение или большее количество деталей - это другой порядок качества. Появление HDTV компания ATI сравнивает с переходом от черно-белых изображений к цветным: большинству людей, видевших HDTV “вживую”, будет трудно вернуться к обычному качеству.
Впечатления от HD Gaming на персональных компьютерах ATI оценивает так же, как ощущения при переходе от обычного качества видео к HDTV: это стабильно высокая частота смены кадров в самых высоких разрешениях, включая 1600х1200 и 1920х1080, невероятная детализация, новый уровень качества картинки, реалистичные эффекты и по-настоящему живые миры.
Архитектура X800, способная воплотить HD Gaming, включает в себя ряд как совершенно новых, так и унаследованных от предыдущей архитектуры, но усовершенствованных технологий. Маркетинговые названия технологий сохранились, но теперь вместо цифровых индексов ATI добавляет к ним суффикс “HD”:
SMARTSHADER HD – вершинные и пиксельные процессоры X800
SMOOTHVISION HD – алгоритмы анизотропной фильтрации и полноэкранного сглаживания
HYPER Z HD – технологии, повышающие эффективность использования доступной пропускной способности шины памяти
3Dc – новый метод компрессии, обеспечивающий сжатие карт нормалей
Перед тем, как рассмотреть подробнее то, что скрывается за новыми маркетинговыми названиями, приведем сравнительную таблицу характеристик самых производительных графических процессоров нового и предыдущего поколений: ATI RADEON X800 XT Platinum Edition, ATI RADEON 9800 XT, NVIDIA GeForce 6800 Ultra и NVIDIA GeForce FX 5950 Ultra:
| ATI RADEON X800 XT Platinum Edition | ATI RADEON 9800 XT | NVIDIA GeForce 6800 Ultra | NVIDIA GeForce FX 5950 Ultra | |
|---|---|---|---|---|
| Технологический процесс | 0.13 мкм low-k | 0.15 мкм | 0.13 мкм | 0.13 мкм |
| Число транзисторов | 160 млн. | 110 млн | 220 млн | 125 млн |
| Тактовая частота | 520 МГц | 412 МГц | 400 МГц | 475 МГц |
| Контроллер видеопамяти | 256 бит DDR/DDR2/GDDR3 SDRAM | 256 бит DDR/DDR2 SDRAM | 256 бит DDR/DDR2/GDDR3 SDRAM | 256 бит DDR SDRAM |
| Тактовая частота видеопамяти | 1120 (560 DDR) МГц | 730 (365 DDR) МГц | 1100 МГц | 950 (475 DDR) МГц |
| Пиковая пропускная способность шины видеопамяти | 33.4 ГБ/сек | 21.8 ГБ/сек | 32.8 ГБ/сек | 28.3 ГБ/сек |
| Максимальный объем видеопамяти | 512 МБ | 256 МБ | 512 МБ | 256 МБ |
| Интерфейс | AGP 3.0 4x/8x | AGP 3.0 4x/8x | AGP 3.0 4x/8x | AGP 3.0 4x/8x |
| Пиксельные процессоры, пиксельные шейдеры | ||||
| Модель шейдеров | 2.x | 2 | 3 | 2.x |
| Статические переходы | да | нет | да | нет |
| Динамические переходы | нет | нет | да | нет |
| Рендеринг в несколько буферов одновременно (Multiple Render Targets) | да | да | да | нет |
| Рендеринг в буфер с плавающей точкой (FP Render Target) | да | да | да | нет |
| Максимальное число выводимых пикселов за такт | 16 | 8 | 16 | 4 |
| Mаксимальное число выводимых значений Z за такт | 16 | 8 | 32 | 8 |
| Число блоков выборки текстур | 16 | 8 | 16 | 8 |
| Типы фильтрации текстур | Билинейная, трилинейная, анизотропная, трилинейная + анизотропная | Билинейная, трилинейная, анизотропная, трилинейная + анизотропная | Билинейная, трилинейная, анизотропная, трилинейная + анизотропная | Билинейная, трилинейная, анизотропная, трилинейная + анизотропная |
| Максимальная степень анизотропии | 16х | 16x | 16x | 8x |
| Вершинные процессоры, вершинные шейдеры | ||||
| Модель шейдеров | 2.х | 2 | 3 | 2.x |
| Число вершинных процессоров | 6 | 4 | 6 | 3 |
| Статические переходы | да | да | да | да |
| Динамические переходы | нет | нет | да | да |
| Чтение текстур из вершинного шейдера | нет | нет | да | нет |
| Тесселляция | нет | нет | нет | нет |
| Полноэкранное сглаживание | ||||
| Методы полноэкранного сглаживания | Мультисэмплинг на повернутой сетке,`темпоральное сглаживание` | Мультисэмплинг на повернутой сетке | Суперсэмплинг на упорядоченной решетке, мультисэмплинг на повернутой сетке, суперсэмплинг + мультисэмплинг | Суперсэмплинг, мультисэмплинг, суперсэмплинг + мультисэмплинг на упорядоченной сетке |
| Число сэмплов | 2,4,6 | 2,4,6 | 2..8 | 2..8 |
| Технологии провышения эффективности использования пропускной способности шины памяти | ||||
| Удаление невидимых поверхностей (HSR) | да | да | да | да |
| Компрессия текстур/ z-буфера/ буфера кадра | да | да | да | да |
| Быстрая очистка z-буфера | да | да | да | да |
Глядя на приведенные в таблице характеристики, можно сделать вывод: благодаря более высокой тактовой частоте RADEON X800 XT Platinum Edition в целом не должен уступать NVIDIA GeForce 6800 Ultra по производительности. Различия в функциональности, конечно, будут присутствовать: ATI не заявляет о поддержке шейдеров модели 3.0 в RADEON X800.
Впрочем, обо всем – по порядку.
Пиксельные конвейеры, пиксельные шейдеры
Первое, что бросается в глаза при рассмотрении особенностей RADEON X800 – повышенные тактовые частоты и увеличенное количество пиксельных конвейеров в новых графических процессорах от ATI: 16 у RADEON X800 XT Platinum Edition и 12 у RADEON 9800 PRO.
Впрочем, говорить о том, что RADEON X800 XT и X800 PRO имеют, соответственно, 16 и 12 пиксельных конвейеров – не совсем корректно, несмотря на то, что, например, на упрощенной блок-схеме RADEON X800 можно увидеть те самые 16 конвейеров:
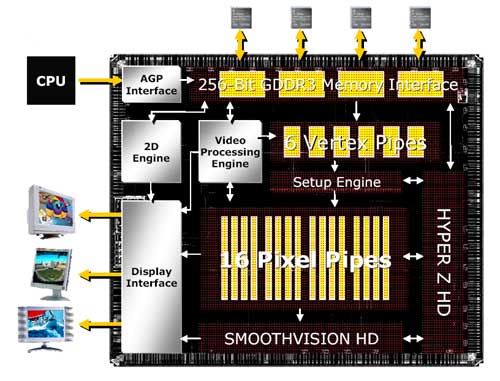
16 пиксельных конвейеров RADEON X800 объединены в 4 группы по 4 конвейера. Иными словами, RADEON X800, по сути, имеет не 16 пиксельных конвейеров, а всего 4, но каждый из таких «широких» пиксельных конвейеров работает не с единичными пикселами, а с группами, состоящими из четырех пикселов.
Соответственно, XT-версия RADEON X800 имеет четыре таких конвейера, что соответствует 16 «обычным» пиксельным конвейерам, а PRO – всего три: RADEON X800 PRO способен выводить 12 пикселов за такт.
Что примечательно, физически все версии графических процессоров RADEON X800 идентичны, все имеют полное число «широких» пиксельных конвейеров, но лишь RADEON X800 XT использует все четыре конвейера. У RADEON X800 PRO один из конвейеров отключен, а на RADEON X800 SE отключены уже два конвейера. Такая практика очень удобна для ATI: когда кристаллы для всех версий графических процессоров изначально одинаковы, отключив те конвейеры, в которых при тестировании были найдены неисправности, можно использовать дефектные чипы для менее производительных решений и тем самым снизить число кристаллов, отправляющихся в брак. Интересно, что, по заявлениям ATI, при отключении конвейеров работоспособность HyperZ HD сохранится. То есть, ситуация с отключением у RADEON 9800 SE как половины конвейеров, так и HyperZ, что приводило к еще более заметному снижению производительности “урезанного” решения – в прошлом.
Но вернемся к пиксельным конвейерам R420.
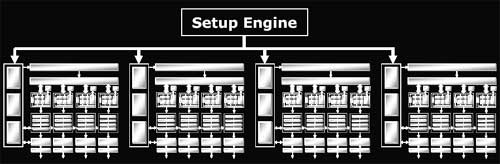
Итак, каждый из четырех «широких» конвейеров RADEON X800 обрабатывает по четыре пиксела – они расположены блоком 2х2 (Quad). Одновременно в обработке - в очереди - может находиться несколько (десятки или сотни) блоков 2х2: такая организация работы позволяет замаскировать латентность выборки и фильтрации текстур, которая может измеряться десятками и сотнями тактов.
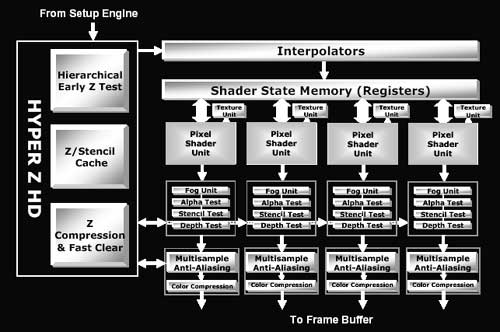
Каждый “широкий” конвейер работает независимо от других и имеет собственные независимые ресурсы – блоки выборки текстур, пиксельные процессоры, и, наконец, кэш-память пиксельных процессоров (Shader State Memory), в которой для каждого пиксела сохраняется информация о состоянии исполнения текущего шейдера, временные регистры и константы, интерполированные текстурные координаты и цвет и т.д..
Количество доступных временных регистров, доступных для использования в ходе исполнения шейдера, в R420 было увеличено по сравнению с R3x0, с 12 до 32. Таким образом, R420 оказался еще более нечувствительным к сложности шейдера – пиксельные процессоры архитектуры NV3x от NVIDIA резко теряли эффективность при исполнении сложных шейдеров, требующих задействования большого числа временных регистров.
Внутренняя точность вычислений с плавающей точкой в пиксельных процессорах при переходе к новой архитектуре не изменилась: RADEON X800 поддерживает представление данных в 16-битном и 32-битном формате с плавающей точкой, но все вычисления производит с 24-битной точностью.
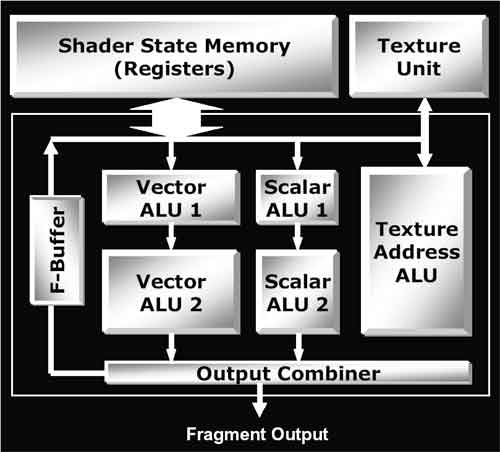
Вычислительная мощность пиксельных процессоров RADEON X800 по сравнению с предыдущей архитектурой серьезно увеличена: число скалярных и векторных арифметико-логических устройств (ALU) теперь увеличено вдвое. Если раньше пиксельные процессоры от ATI, имея одно векторное ALU, одно скалярное ALU и один блок адресации текстур, могли в сумме за один такт исполнить до трех инструкций над каждым пикселом, то в RADEON X800 число скалярных и векторных ALU удвоено, и в результате пиксельные процессоры могут исполнить до пяти инструкций над каждым пикселом за один такт.
Помимо всех прочих усовершенствований, пиксельные процессоры RADEON X800 получили возможность исполнять более длинные шейдеры: по сравнению с предыдущим поколением максимальное число скалярных и векторных математических инструкций было увеличено с 64 до 512, а число текстурных инструкций – с 32 до 512. В сумме максимальное число текстурных инструкций, а также скалярных и векторных математических инструкций увеличилось со 160 до 1536.
Кардинальное увеличение максимального количества инструкций в шейдере позволяет RADEON X800 эффективно исполнять значительно более сложные и ресурсоемкие пиксельные шейдеры. Если же шейдер окажется настолько сложным, что ресурсов графического процессора окажется недостаточно для его исполнения за один проход, графические процессоры серии RADEON X800 могут исполнить его в несколько приемов – шейдер будет разбит на несколько фрагментов, которые будут исполнены поочередно, а промежуточные результаты между проходами будут сохраняться в в специально предназначенном для этого буфере – Fragment Sream FIFO Buffer – том же самом F-Buffer’e, который официально появился в арсенале графических процессоров от ATI вместе с анонсом RADEON 9800/9800 PRO, но с некоторыми усовершенствованиями, предназначенными для повышения эффективности исполнения многопроходных шейдеров.
Имея расширенную функциональность по сравнению с предыдущей архитектурой, ATI RADEON X800, тем не менее, не поддерживает динамические переходы и циклы в пиксельных шейдерах. Поэтому ATI не может заявить о поддержке пиксельных шейдеров модели 3.0 - в отличие от 2.х, для шейдеров 3.0 поддержка динамических переходов и циклов является обязательным условием.
ATI, несомненно, положительно оценивает преимущества модели 3.0, но полагает, что время шейдеров 3.0 пока не пришло - использование динамических переходов на существующих архитектурах неизбежно приводит к снижению производительности - о том, что динамические переходы нужно использовать осторожно, предупреждает даже NVIDIA - а это совершенно не то, чего хотят разработчики. К тому же, введение соответствующей поддержки потребовало бы существенного пересмотра архитектуры пиксельных процессоров RADEON X800, изначально не приспособленных к нелинейному исполнению шейдеров. В итоге, взвесив все "за" и "против", инженеры ATI решили отказаться от полноценной поддержки шейдеров 3.0 - вместо этого, скорее всего, появится "урезанный" вариант стандарта без поддержки динамических переходов, который получит название 2.b.
Самым большим преимуществом архитектуры пиксельных процессоров RADEON X800 ATI считает их стабильную эффективность и предсказуемость: в отличие от графических процессоров NVIDIA, RADEON X800, как и предыдущие VPU от ATI, намного спокойнее реагирует на увеличение количества необходимых в ходе исполнения шейдеров временных регистров или изменение соотношения числа математических и текстурных инструкций, а значит, разработчикам будет намного проще создавать шейдеры, которые будут исполняться на RADEON X800 эффективно.
В этом свете особенно примечательно то, что с появлением RADEON Х800 компания ATI, следуя примеру NVIDIA, вводит в драйвер свой вариант оптимизирующего компилятора шейдеров. Возросшую вычислительную мощность пиксельных процессоров RADEON X800 необходимо использовать максимально эффективно, и для того, чтобы минимизировать вероятность возникновения таких ситуаций, при которых часть ALU пиксельных процессоров будет простаивать, компилятор, анализируя исходный код шейдеров, меняет порядок следования и группирует инструкции для того, чтобы максимальное количество инструкций выполнялось параллельно.
Чуть позже по ходу обзора мы обязательно оценим, насколько эффективно RADEON X800 работает с пиксельными шейдерами, а сейчас рассмотрим вершинные конвейеры RADEON X800.
Вершинные конвейеры, вершинные шейдеры.
В первую очередь стоит сказать о том, что количество вершинных процессоров в RADEON X800 увеличено было увеличено до шести - предыдущие графические чипы высшего класса от ATI имели всего 4 вершинных процессора. Добавив к этому значительный рост тактовых частот новых графических процессоров, можно сразу представить минимальный прирост геометрической производительности при переходе на RADEON X800.
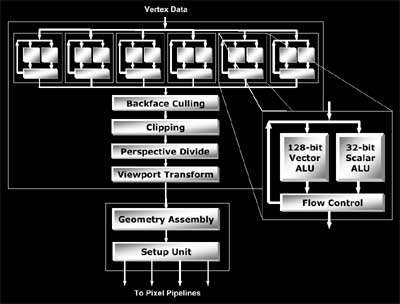
Геометрическая часть RADEON X800 состоит из шести вершинных процессоров и набора непрограммируемых функциональных блоков, осуществляющих проекцию вершин, обработанных пиксельными процессорами, на плоскость экрана, задание начальных параметров для HyperZ и разбиение «собранных» из вершин треугольников на тайлы, задание начальных параметров для пиксельных процессоров, формирование очередей из блоков по 4 пиксела и т.д..
Каждый из вершинных процессоров RADEON X800 имеет два ALU, способных исполнять команды параллельно: векторное и скалярное арифметико-логические устройства. Вычисления производятся в 32-битном формате с плавающей точкой.
Вершинные процессоры RADEON X800 так же, как и пиксельные процессоры, не поддерживают динамические переходы в вершинных шейдерах, что вкупе с отсутствием в вершинных процессорах блоков выборки текстур перечеркивает надежды увидеть в RADEON X800 аппаратную поддержку вершинных шейдеров модели 3.0.
Итак, в части вершинных процессоров RADEON X800 изменения видны, в первую очередь, в количественном плане: имея 6 процессоров конвейеров и высокие тактовые частоты, RADEON X800 должен значительно превосходить графические процессоры предыдущего поколения по геометрической производительности.
Немного дальше по ходу обзора мы сможем оценить скорость исполнения вершинных шейдеров и геометрическую производительность RADEON X800 XT Platinum Edition и RADEON X800 PRO в синтетических тестах, а сейчас остановимся на Hyper Z HD – технологии, призванной повысить эффективность использования ресурсов графического процессора.
HyperZ HD
HyperZ HD- дальнейшее развитие идей иерархического тайлового Z-буфера, реализованных во всех графических процессорах от ATI начиная с RADEON 256.
Основная цель HyperZ HD - с максимальной эффективностью исключить из обработки те пикселы обрабатываемого в данный момент полигона, которые в пространстве сцены находятся позади уже отрисованных ранее и поэтому не войдут в финальное изображение. Простейший пример: если вы находитесь в комнате с закрытой дверью, то зачем делать лишнюю работу и отрисовывать помещение и весь интерьер того помещения, что находится за дверью?
Для эффективного исключения из обработки целых блоков пикселов технология HyperZ HD, помимо "обычного" Z-буфера использует Z-буферы пониженного разрешения, или тайловые Z-буферы. Каждое значение из этих Z-буферов хранит самое большое значение Z, выбранное среди целого блока - тайла - пикселов.
В RADEON X800, судя по всему, используется два тайловых Z-буфера с разным разрешением. Рассмотрим предполагаемую схему работы RADEON X800 c тайловыми иерархическими Z-буферами - ATI называет ее Hierarchical Z.
Получив на обработку полигон, HyperZ HD разбивает его на блоки размером 8х8 пикселов и находит минимальное значение Z среди 64 пикселов каждого блока - очевидно, оно будет достигнуто в одном из угловых пикселов, поэтому для проверки всего блока достаточно рассмотреть лишь 4 значения Z в его угловых точках.
Если это значение Z окажется больше, чем значение, ранее сохраненное для этого блока в тайловом Z-буфере (оно могло быть туда занесено при обработке предыдущих полигонов либо в процессе инициализации Z-буферов в начале построения кадра), то, очевидно, весь блок размером 8х8 пикселов можно исключить из обработки - самый ближний пиксел из этого блока оказывается дальше, чем самый дальний из пикселов, отрисованных ранее.
Если же самое маленькое значение Z для пикселов из блока 8х8 оказывается меньше, чем ранее сохраненное значение Z для этого блока, то, очевидно, блок оказывается частично или полностью виден. В таком случае блок 8х8 разбивается на 4 блока размером 4х4 и аналогичные проверки производятся уже для групп из 16 пикселов.
Значения Z для блоков 4х4 хранит второй Z-буфер пониженного разрешения. Если минимальное значение Z для пикселов из блока 4х4 оказывается больше, чем ранее сохраненное, то блок исключается из рассмотрения.
Наконец, когда выясняется, что блок 4х4 частично или полностью видим, HyperZ HD заканчивает блочные проверки и переходит в "классический режим работы", проверяя значения Z индивидуальных пикселов и сравнению этих значений с величинами, сохраненными в обычном Z-буфере (Early Z Test).
Для того, чтобы вся эта достаточно сложная схема работала корректно, при построении сцены, то есть, отрисовке полигонов, нужно поддерживать информацию в основном Z-буфере и тайловых Z-буферах в актуальном состоянии: записывать в Z-буфер рассчитанные значения Z пикселов, а в два тайловых Z-буфера - максимальные значения Z для блоков размером, соответственно, 4х4 и 8х8 пикселов.
Помимо этого, перед началом отрисовки кадра нужно задать начальное состояние всех Z-буферов. Примечательно, что, благодаря подобной организации работы иерархического Z-буфера для этого нет необходимости в записи начальных значений в основной Z-буфер - вместо этого можно задать лишь начальные значения самого "грубого" тайлового Z-буфера, хранящего значение Z для блоков 8х8, а остальные Z-буферы при построении сцены "сами собой" получат актуальные значения.
Такую возможность ATI называет Fast Z Clear - действительно, вместо записи начальных значений в основной Z-буфер - а это почти 8 МБ при разрешении 1600х1200 - можно записать начальные значения лишь в самый "грубый" тайловый Z буфер, соответствующий блокам 8х8 пикселов и таким образом передать в 64 раза меньший объем данных.
Имея 4 "широких" пиксельных конвейера, за один такт RADEON X800 может проверить Z сразу для четырех блоков размером 8х8 пикселов, и в том случае, когда они оказываются невидимы, за один такт может исключить из рассмотрения сразу 256 пикселов. Прекрасная эффективность, не правда ли?
Помимо повышения эффективности использования ресурсов графического процессора за счет исключения из обработки невидимых пикселов, HyperZ HD значительно сокращает объемы информации, относящейся к Z, которые необходимо передавать по шине памяти - иерархические Z-буферы, в отличие от основного Z-буфера, хранятся целиком в кэше графического процессора, причем, его объема достаточно для того, чтобы даже в самых высоких разрешениях вместить как иерархические Z-буферы, так и необходимые фрагменты основного Z-буфера.
Итак, при сравнении ATI RADEON X800 XT Platinum Edition и RADEON X800 PRO с новейшим графическим процессором от NVIDIA и чипами предыдущего поколения в игровых тестах мы обязательно постараемся оценить эффективность HyperZ HD. А сейчас немного отдохнем от 3D и рассмотрим возможности RADEON X800 в части воспроизведения и обработки видео.
VIDEOSHADER: видео и HDTV
В отличие от разработчиков NVIDIA, снабдивших свое детище, графический процессор NV40, специальными возможностями по обработке видеопотоков, инженеры ATI Technologies при переходе к новой архитектуре справедливо решили, что от добра добра не ищут, и оставили все как есть. Иными словами, механизм работы с видео в R420 остался тем же, что и в линейке R3x0/RV3x0. Впрочем, это не значит, что возможности R420 по обработке видео слабы. Уже со времен RADEON 9700 PRO, видеоадаптеры ATI умеют использовать для этой цели вычислительные ресурсы пиксельных процессоров - технология VIDEOSHADER - так что с обработкой видео у RADEON X800 все в порядке. С помощью VIDEOSHADER графический процессор выполняет деинтерлейсинг, шумоподавление, конверсию цветовых пространств, а также своего рода сглаживание изображения, позволяющее убирать блочные артефакты, свойственные методам сжатия MPEG-4/DivX.
Как и в случае с любым новым графическим процессором, мы протестировали ATI RADEON X800 при проигрывании видео самых различных форматов: HDTV, MPEG-4/DivX и MPEG-2/DVD. Во всех трех случаях использовался Windows Media Player 9.
Для удобства мы свели полученные данные тестирования, полученные на R420, NV40 и DeltaChrome S8, в удобные для восприятия диаграммы:

При проигрывании HDTV на картах c чипами ATi и S3 никаких особых сюрпризов не возникло – для такого высококачественного видеопотока уровень загрузки центрального процессора оказался вполне приемлемым . Видеокарта, основанная на GeForce 6800 Ultra, не смогла нормально пройти этот тест из-за проблем с драйверами: загрузка ЦП всякий раз поднималась до 100%.
Проигрываемый ролик имел разрешение 1440х1080 и битрейт 8 Мбит/сек.
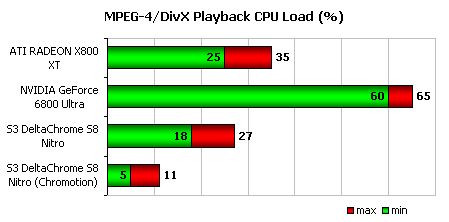
Проигрывая ролик с разрешением 640x480, закодированный кодеком DivX, новинка также показала хороший результат, хотя уровень загрузки ЦПУ оказался чуть выше, нежели на S3 DeltaChrome S8 Nitro в обычном режиме. При задействовании возможностей движка Choromotion видеокарта, основанная на чипе от S3, показала наилучший результат.
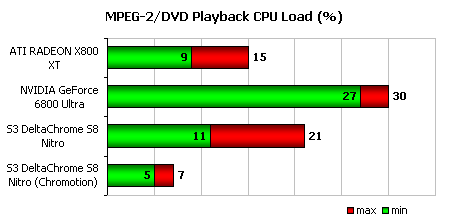
Тест с проигрыванием DVD также не вызвал каких-либо проблем, причем, RADEON X800 XT продемонстрировал в нем наилучший результат среди тех плат, что не используют особые функции ускорения декодирования видео. Даже при задействовании движка Chromotion видеокарта на базе S3 DeltaChrome S8 Nitro показала лишь немногим более низкий уровень загрузки процессора.
Что же касается качества изображения при проигрывании роликов, то во всех случаях оно было примерно одинаковым, и никаких нареканий по этому поводу у нас не возникло.
3Dc: новый алгоритм компрессии карт нормалей
С появлением RADEON X800 компания ATI представила новый алгоритм компрессии, специально предназначенный для сжатия карт нормалей - 3Dc.
Карты нормалей являются дальнейшим развитием технологий имитации рельефности, и в настроящее время получают всё большее распространение. Суть карт нормалей состоит в сохранении информации о неровностях объекта в виде текстур, где каждый элемент текстуры хранит три компоненты вектора, перпендикулярного поверхности объекта в данной точке, то есть, вектора нормали.
Применение карт нормалей позволяет получить граздо более детальное и реалистичное изображение объекта, не увеличивая при этом число полигонов, описывающих этот объект. Соответственно, для создания карт нормалей для объекта достаточно создать высокополигональную модель и упрощенную модель объекта и на основании разницы между этими моделями создать карту нормалей. В дальнейшем можно использовать лишь упрощенную модель, но при применении ранее созданной карты нормалей внешний вид объекта даже при применении более простой модели будет близок к исходному виду:
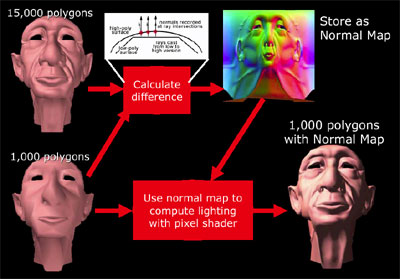
Обычно карты нормалей, описывающие неровности объекта, применяются совместно с базовыми текстурами, хранящими цветовую информацию о поверхности объекта. Чем более детальными будут текстуры и карты нормалей, тем более реалистичным получится изображение объекта. Однако, применение текстур и карт нормалей высокого разрешения увеличивает нагрузку на шину памяти, поэтому для сохранения высокой производительности приходится искать компромиссные варианты. DirectX9 предлагает семейство алгоритмов DXTC, обеспечивающих эффективную компрессию текстур, и они, несмотря на потери информации при компрессии, сохраняют качество текстур на приемлемом уровне. Но для компрессии карт нормалей использование DXTC не подходит - резкие изменения вектора нормали после компрессии теряются, а вместо этого карта нормалей приобретает блочные артефакты.

Аппаратно поддерживаемый графическими процессорами RADEON X800 алгоритм 3Dc специально предназначен для компрессии карт нормалей и обеспечивает намного менее заметные потери в качестве изображения.
Рассмотрим принцип 3Dc чуть более подробно.
Во-первых, в отличие от исходных карт нормалей, хранящих в каждом элементе по три компоненты вектора нормали, 3Dc сохраняет только две компоненты. Приведя вектор нормали к единичной длине, можно отказаться от хранения одной из компонент - в дальнейшем ее можно будет восстановить по известной - единичной - длине вектора и координатам двух оставшихся нормалей.
При компрессии двухкомпонентных карт нормалей 3Dc использует разбиение на блоки размером 4х4 элемента, где каждый элемент состоит из двух компонент вектора нормали. Компоненты, составляющие 16 элементов блока, сжимаются раздельно: найдя максимальное и минимальное значение среди 16 первых компонент элементов блока, 3Dc сохраняет их в неизменном виде. Далее на отрезке между найденным минимумом и максимумом выстраивается линейная шкала, состоящая из 8 значений. Для каждой из 16 первых компонент элементов блока ищется наиболее близкое значение из линейной шкалы, и присваивается трехбитный индекс - порядковый номер самого близкого значения из линейной шкалы.
Вторые компоненты карты нормалей сжимаются аналогичным образом. В результате блок 4х4, изначально состоявший из 16 элементов, содержащих по 2 восьмибитных компоненты вектора нормали, то есть, имевший размер 256 бит, превращается в запись, состоящую из двух 8-битных минимальных значений, двух 8-битных максимальных значений и 32 трехбитных индексов - в сумме 128 бит.
Таким образом, при компрессии двухкомпонентных карт нормалей 3Dc обеспечивает сжатие с соотношение 2:1. В сумме же с переходом от обычной записи векторов нормалей к двухкомпонентной обеспечивается сжатие с соотношнием 4:1.
При использовании карт нормалей, упакованных методом 3Dc RADEON X800 хранит их в видеопамяти и передает графическому процессору в сжатом виде, при использовании распаковывая их «на лету». Восстановление третьей компоненты вектора нормали в пиксельном шейдере не требует серьезных затрат – для этого достаточно добавить в шейдер лишь несколько дополнительных команд.
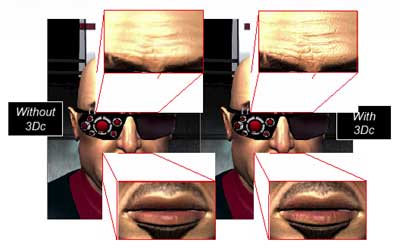
Итак, использование нового метода компрессии карт нормалей позволяет снизить нагрузку на шину памяти при использовании высокодетализированных карт или, наоборот, сохранив объемы данных на том же уровне, увеличить детализацию карт нормалей.
Третья часть:
Анизотропная фильтрация
Анизотропная фильтрация: производительность
Полноэкранное сглаживание
Полноэкранное сглаживание: производительность
Полноэкранное сглаживание: Temporal Antialiasing
Четвертая часть:
Драйверы, настройки и конфигурация тестового стенда
Синтетические тесты: cкорость заполнения
Синтетические тесты: пиксельные шейдеры
Синтетические тесты: вершинные процессоры
Синтетические тесты: TnL, спрайты, EMBM и т.д.
Выводы по результатам синтетических тестов
Пятая часть:
Игровые тесты: RTCW: Enemy Territory
Игровые тесты: Call of Duty
Игровые тесты: Unreal Tournament 2003
Игровые тесты: Unreal Tournament 2004 Demo
Игровые тесты: Halo: Combat Evolved
Игровые тесты: Tron 2.0
Игровые тесты: FarCry
Игровые тесты: Firestarter
Игровые тесты: Painkiller
Игровые тесты: Tom Clancy’s Splinter Cell: Pandora Tomorrow
Игровые тесты: Tomb Raider: Angel of Darkness
Игровые тесты: Prince of Persia: Sands of Time
Игровые тесты: Max Payne 2: The Fall of Max Payne
Игровые тесты: Star Wars: Knights of The Old Repubilc
Игровые тесты: IL-2 Sturmovik: Forgotten Battles
Игровые тесты: Lock On
Игровые тесты: X2: The Treat
Игровые тесты: F1 Challenge 99-2002
Игровые тесты: Colin McRae Rally 04
Игровые тесты: C&C Generals: Zero Hour
Полусинтетические тесты: Final Fantasy XI Official Benchmark 2
Полусинтетические тесты: Aquamark3
Полусинтетические тесты: Futuremark 3DMark03 build 340
Заключение



© 1998-2023 fcenter.ru | Россия
© 1998-2023 fcenter.ru | Россия