Ваш город: Москва
Prescott: Последний из могикан? (Pentium 4: от Willamette до Prescott). Часть 3
Глава шестая, погружающая нас в глубоко интимные подробности
Ну что ж, настало время рассмотреть подробно конвейер процессора Pentium 4. Тем более, что на самом деле подробной информации о нем практически нет. Известно только, что в ядре Northwood конвейер (та часть, которая расположена после Trace cache) занимает 20 стадий, а у ядра Prescott и того больше, 31 стадию.
Давайте рассмотрим конвейер ядра Northwood подробнее, указывая, какая работа исполняется на каждой из стадий:

1. TC Nxt IP 1
2. TC Nxt IP 2: на этих двух стадиях Trace cache находит те микрооперации, на которые указывает последняя выполненная инструкция
3. TC Fetch 1
4. TC Fetch 2: на этих двух тактах выбирается до шести микроопераций, которые направляются в специальную очередь (обозначим ее Fetch Queue), в которой порядок следования микроинструкций полностью соответствует первоначальному коду. Если среди микроинструкций "затесался" MROM-вектор, дальнейшее считывание из Trace cache приостанавливается, и вместо MROM-вектора в очередь Fetch Queue направляется обозначенная им последовательность микроопераций. Напомним, что, по сути, Trace cache работает на половине номинальной частоты!
5. Drive: микрооперации перемещаются в направлении специального устройства (allocator). На этой стадии никаких изменений с микрооперациями не происходит, они просто движутся по конвейеру. По всей видимости, необходимость в этой стадии возникла потому, что на тех частотах, на которых работает конвейер, микрооперации не всегда успевают достичь устройства за один такт.
6. Allocator: на этой стадии специальное устройство выбирает из очереди Fetch Queue по три микрооперации, для которых резервируются необходимые ресурсы процессора: место в очередях, элементы регистрового файла и буфера переупорядочивания инструкций. Подготовленные таким образом операции передаются в другие очереди, которые мы назовем uopQ. Кроме того, на этом этапе для микроопераций резервируются места в ROB (Reorder Buffer), эта информация понадобится при отставке микроинструкций.
7. Rename registers 1
8. Rename registers 2: на этих стадиях логические регистры отображаются на реальные физические регистры. Логических регистров общего назначения в IA32 всего восемь, а физических регистров гораздо больше, 128. Эта операция необходима для того, чтобы несвязанные друг с другом команды могли обрабатываться независимо, не ожидая, пока освободится необходимый регистр. Порядок микроопераций соответствует исходному коду программы.
9. Queue: на этой стадии подготовленные Allocator-ом микрооперации сортируются и размещаются в специальных очередях, uopQ. Очередей uopQ две. Одна из них предназначена для операций вычисления адреса, другая – для всех остальных микроопераций. Порядок микроопераций соответствует коду программы. Из очередей uopQ микрооперации отправляются в очереди планировщиков, schQ. Ниже в этой главе очереди uopQ и schQ будут освещены более подробно.
10. Schedule 1
11. Schedule 2
12. Schedule 3: на этих трех стадиях происходит множество интересных вещей. Во-первых, планировщики (schedulers) принимают из очередей uopQ микрооперации. Причем выбирают строго наиболее старые операции с сохранением их порядка, но из двух очередей uopQ микрооперации выбираются независимо друг от друга. Кроме того, на каждый планировщик направляются именно те микрооперации, которые соответствуют его типу; затем они помещаются в очередь schQ. Всего существует пять планировщиков. И, соответственно, всего существует пять очередей schQ. Тип микрооперации однозначно определяет, в очередь какого планировщика попадет микрооперация. Из очередей schQ микрооперации направляются на исполнение через порты запуска, issue ports (или execution ports). Всего имеется четыре порта.
13. Dispatch 1
14. Dispatch 2: на этих стадиях микрооперации готовятся к исполнению и снабжаются соответствующими операндами. Далее они через порты запуска (issue ports) пойдут на соответствующие исполнительные устройства. Порядок исполнения микроопераций соответствует их готовности и не соответствует первоначальному коду программы.
15. Register File 1
16. Register File 2: на этих стадиях производится чтение операндов из регистрового файла. Напомним, что из регистрового файла чтение может производиться на удвоенной частоте, поскольку это необходимо для работы fast ALU.
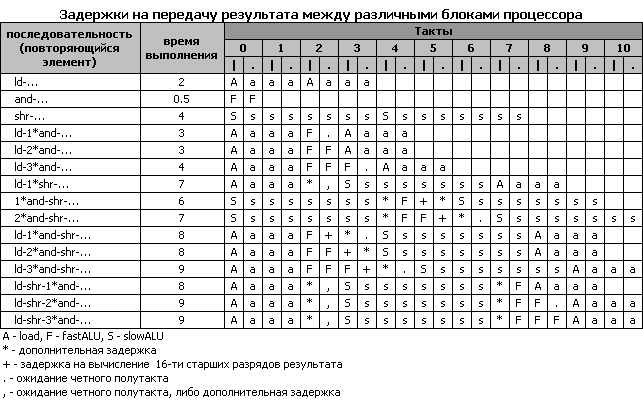
17. Execute: та самая стадия, ради которой и создавалась вся эта сложная конструкция. Именно на этой стадии только что пришедшая микрооперация, снабженная операндами, попадает на свое функциональное устройство и выполняется. Важно отметить: результат исполнения может быть немедленно "подхвачен" ожидающей его операцией параллельно записи в Register File (механизм, называемый bypass). Вместо использования "правильной", но долгой последовательности "вначале сохранить данные в регистр, а потом считать его оттуда" мы сразу направляем результат на ожидающий его блок. "Немедленная" передача результата происходит даже между двумя различными fast ALU; в других же случаях могут возникать небольшие задержки как на синхронизацию данных, так и на их передачу (см. Приложение 2).
18. Flags: На этой стадии вычисляются и устанавливаются флаги, которые необходимы для исполнения программы. Например, нулевой результат, положительный, флаг готовности и прочие. В частности, эти флаги являются входящими данными для следующей стадии, на которой будет происходить проверка правильности предсказанных переходов.
19. Branch Check: на этой стадии модуль предсказания переходов сравнивает предсказанный для только что выполненной команды адрес перехода с тем, который предсказывался ранее. И, если предсказание оказалось ошибочным, алгоритм предсказания будет скорректирован. Таким образом модуль предсказания переходов набирает статистику точности предсказания, которая используется для корректировки модели предсказания.
20. Drive: Результат проверки, полученный на предыдущей стадии, направляется в декодер.
Микрооперация ждет отставки (retirement) для освобождения выделенных ей ресурсов и окончательной записи неспекулятивных результатов. Отставка, выполняемая строго последовательно (по отношению к коду программы), производится над теми же тройками микроопераций, которые были сформированы на ранних стадиях конвейера, со скоростью одна тройка в такт. Важный нюанс: если одна из троек микроопераций еще не готова, система будет ожидать завершения вычислений. Для отставки используется информация о первоначальном порядке микроинструкций, которая была записана в ROB на стадии 6, занимается этим процессом Retire Unit, находящийся в самом конце конвейера.
Приведем принципиальную схему конвейера, которая послужит иллюстрацией к вышесказанному:
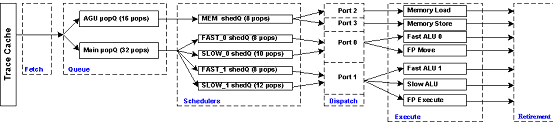
Внимательный читатель уже обратил внимание, что на многих стадиях конвейера у нас появились новые "герои", о которых ранее было известно достаточно мало. Эти "герои" – всевозможные очереди, которых насчитывается не менее трех различных видов. В связи с тем, что ранее мы их не рассматривали, дадим более развернутую информацию о них.
Итак, на стадии 6 (Allocator) мы выбираем из единственной очереди Fetch Queue по три микрооперации, для которых резервируются внутренние ресурсы процессора. Затем они размещаются в двух очередях uopQ. Одна из них для адресных операций, другая – для всех остальных. Как несложно заметить из нашего объяснения конвейера, размещаются микрооперации в двух этих очередях на стадии 9 (Queue).
Основная задача очередей uopQ состоит в распределении разнотипных микроопераций по соответствующим планировщикам. Именно в связи с этим uopQ для адресных операций принимает только два типа микроопераций: "load [address]" и "store address"; все иные операции, в том числе и "store data", помещаются в другую, основную очередь. Глубина адресной очереди – 16 микроопераций, очередь для основных микроопераций вмещает вдвое больше, 32 микрооперации. Постановка микроопераций в очереди происходит последовательно: переполнение одной из очередей делает вторую очередь недоступной для записи. Два практических бонуса от подобной организации очередей: "ранняя" загрузка и возможность ускоренного выполнения коротких участков кода, зависимых от результата длительных операций.
При обработке планировщиками (стадии 10, 11, 12) микрооперации распределяются по следующему типу очередей, очередям планировщиков.
Отправка микроопераций из очередей uopQ также происходит последовательно, по принципу FIFO (first in – first out). Здесь уже очереди работают независимо друг от друга: например, микрооперация из "адресной" очереди может быть выбрана до того, как другие предшествующие ей микрооперации покинут "основную" очередь. Во многих случаях это дает очень полезную возможность приступить к загрузке данных заранее. Но есть и другая сторона медали: такая независимость друг от друга существенно увеличивает вероятность некорректных ситуаций, таких как попытка преждевременного считывания данных еще до того, как они были вычислены в соответствующей микрооперации основной очереди.
При этом темп отправки значителен: до двух микроопераций на такт для каждого планировщика, причем не только для "быстрых" планировщиков (см. ниже) – для "медленных" планировщиков подобная скорость также достижима. Очереди uopQ очень четко реагируют на полутактовые события (и, таким образом, также могут быть причислены к устройствам, которые работают на удвоенной частоте). В том случае, если микрооперацию, подошедшую к концу очереди, нельзя направить на планировщик из-за переполнения его очереди schQ, отправка всех остальных микроопераций из очереди uopQ приостанавливается. Если микрооперация может быть направлена на один из двух планировщиков, то система может производить выбор в зависимости от состояния очередей планировщиков schQ.
Очередей, как и планировщиков, всего пять, это мы уже указывали в описании конвейера. Перечислим эти планировщики:
FAST_0 – работает с ALU микрооперациями: логические операции (and, or, xor, test, not); ALU store data; branch; операции пересылки (mov reg-reg, mov reg-imm, movzx/movsx, простые формы lea); простые арифметические операции (add/sub, cmp, inc/dec, neg).
FAST_1 – работает с ALU микрооперациями. Сюда относятся подмножества операций пересылки (без movsx) и арифметических операций (без neg). Видимо, все операции, посылаемые на FAST1, могут быть направлены и на FAST0.
SLOW_0 – работает с FPU микрооперациями, связанными с пересылкой и конвертацией данных (для x87, MMX, SSE, SSE2-инструкций); также FPU store data.
SLOW_1 – работает с ALU- и FPU микрооперациями: ряд простых ALU-операций (shift/rotate; некоторые микрооперации, порождаемые adc/sbb) и все более сложные, начиная с умножения; основная масса "вычислительных" FPU-операций.
MEM – AGU-операции: load и store address.
Очевидно, что операции из адресной очереди uopQ направляются в очередь планировщика MEM. Все остальные микрооперации попадают в очередь одного из четырех планировщиков.
Мы уже говорили, что не только fast ALU работают на удвоенной относительно номинальной частоте, есть и другие блоки в процессоре, которые тоже работают вдвое быстрее номинала. К таким блокам относятся два планировщика FAST_0 и FAST_1, обслуживающие каждый свое fast ALU. Это касается выборки и отправки микроопераций; в некоторых случаях, например для "ALU store data" микроопераций, принимающий их блок не в состоянии обеспечить соответствующую скорость. В результате этого микрооперации могут быть направлены на подобные блоки только на четных полутактах.
Очереди schQ, по сути соответствующие станциям резервирования (reservation station, RS) в микроархитектуре Р6, обеспечивают выборку с изменением последовательности. Соответственно, именно в этом месте происходит внеочередная выборка команд.
Операции отправляются на исполнение таким образом, что к моменту их прибытия на функциональное устройство оно как раз должно освободиться, а операнды микрооперации стать доступными. Если в какой-то момент для отдельной очереди schQ условиям удовлетворяет несколько операций, то, как правило, преимущество отдается наиболее "старой".
Как видно из вышесказанного, планировщики выполняют ту подготовительную работу, без которой эффективно работать процессор не может. По сути, именно планировщики являются "сердцем" логики, обслуживающей функциональные устройства. В частности, планировщики должны эффективно "кормить" функциональные устройства командами и данными, чтобы последние как можно меньше простаивали. Но для качественного планирования загрузки исполнительных устройств необходимо, кроме всего прочего, точно знать времена исполнения всех микроопераций и время подхода нужных нам операндов. Времена исполнения большинства команд фиксированы и хорошо известны. Проблемы начинаются, когда время доставки данных (особенно в случае доставки из памяти) является плохо предсказуемым.
В связи с тем, что путь, проходимый микрооперацией от планировщика до функционального устройства, включает несколько стадий конвейера, планировщику необходимо вычислять / предсказывать состояние машины вперед на несколько тактов. Для микроопераций, зависимых от тех, чье время выполнения может быть непостоянным (например, загрузка данных), делаются определенные допущения. Мысленно поставим закладку в этом месте: позднее нам понадобится воспоминание об этой особенности работы планировщика для объяснения работы реплея.
Размеры очередей schQ: SLOW_1 – 12 позиций, SLOW_0 – 10 позиций, остальных – по 8 позиций. Эти цифры определяют максимальную ширину "окна" для однотипных инструкций, среди которых возможно изменение порядка исполнения. Подчеркнем этот ключевой момент: качество работы логики внеочередного исполнения команд зависит от размера очередей планировщиков.
После обработки планировщиками микрооперации запускаются на исполнение через порты запуска, которых четыре штуки:
За порт №0 конкурируют планировщики FAST_0 и SLOW_0; за порт №1 - FAST_1 и SLOW_1. Load-микрооперации и store-address-микрооперации отправляются планировщиком MEM в порт №2 и порт №3 соответственно. Порты №0 и №1 принимают операции с "быстрых" планировщиков каждых полтакта, с "медленных" – каждый второй (четный) полутакт. Один порт в течение полутакта может обработать только одну операцию; в случае конфликта двух планировщиков выбирается, как правило, наиболее "старая" микрооперация. Система обеспечивает считывание регистров из Register File на удвоенной частоте.
Порты запуска для fast ALU, также как и планировщики, работают на удвоенной частоте. Планировщики, регистровый файл, порты запуска и fast ALU вместе составляют так называемый Rapid Execution Engine.
Напомним, что мы только что обсудили устройство конвейера для ядра Northwood. Известно, что конвейер ядра Prescott имеет длину 31 стадию, то есть заметно длиннее. Однако новые стадии, появившиеся там, это в основном стадии Drive, когда происходит простая передача микрооперации или данных далее по конвейеру, без обработки.
Глава седьмая, проясняющая разницу между делением "по-братски" и делением "по справедливости"
С нашей точки зрения, наступило самое удобное время для того, чтобы припомнить о широко разрекламированной технологии Hyper Threading (НТ). Основная идея этой технологии проста и понятна: при исполнении программного кода практически никогда не бывает ситуации, чтобы были задействованы все (или хотя бы большинство) исполнительных блоков процессора. Как правило, в среднем при работе процессора задействуется лишь треть доступных вычислительных ресурсов (оценка корпорации Intel), что, согласитесь, до определенной степени просто унизительно!
Соответственно, возникла следующая мысль: если часть вычислительных блоков не занята текущей, исполняющейся в данный момент программой, нельзя ли их использовать для выполнения другой программы (либо другой нити этой же программы) в этот же момент времени? Что ж, идея вполне здравая. Впервые, кстати, эта идея зазвучала в 1978 году, затем позднее была реализована Cray в CDC6600 (правда, тогда процессор был отнюдь не однокристальным). В то время она называлась Simultaneous Multi Threading. Поэтому нельзя сказать, чтобы Intel была абсолютно оригинальной в этой идее. Тем не менее, на рынок персональных компьютеров эту технологию вывела именно Intel.
Каким же образом работает эта технология? Основополагающая идея вроде бы понятна, но как именно реализовано исполнение одновременно нескольких задач?
Наиболее простым и логичным образом. Процессор, обладающий технологией Hyper Threading, представляется операционной системе в виде двух логических процессоров. Таким образом, работать с такими процессорами могут лишь те операционные системы, которые корректно работают в многопроцессорных конфигурациях. Каждому из логических процессоров соответствует некоторое "архитектурное состояние", которое описывается набором значений логических регистров, служебных флагов и регистров состояния. Эти "архитектурные состояния" для двух процессоров отличаются, и обслуживающая их логика должна уметь обрабатывать состояния каждого логического процессора отдельно. Такие блоки необходимо добавить в процессор.
В целом, процессор можно условно разделить на две части: два набора "архитектурных состояний", описывающие наши два логических процессора, и общее для обоих логических процессоров ядро, которое, собственно, и исполняет команды. Несколько упрощая ситуацию, можно сказать, что реализующие Hyper Threading устройства в заметной степени являются частью Front End группы устройств.
Итак, для поддержки Hyper Threading понадобилось добавить в процессор следующие устройства (точнее, пришлось продублировать часть уже существующих устройств): Instruction Streaming Buffers, Instruction TLB, Trace Cache Next IP, Trace Cache Fill Buffers, Register Alias Tables. При этом добавленные устройства увеличивают площадь кристалла совсем несущественно, менее 5%. Проиллюстрируем это:

На рисунке изображен процессор Intel® Xeon™ MP с 256KB кэша второго уровня и
1MB кэша третьего уровня, производимый по технологическому процессу 0.18 микрон
Таким образом, большинство устройств, добавленных в процессор, представляют собой специализированные буферы, сохраняющие архитектурные состояния логических процессоров.
После этого принцип разделения понятен: различные программы (либо различные нити одной программы) просто направляются на различные логические процессоры. Разница только в том, что все эти программы исполняются на одном физическом процессоре. И, казалось бы, наибольший выигрыш в производительности должен достигаться тогда, когда две запущенные программы используют разные исполнительные блоки.
Действительно, вполне логично предположить, что запуск двух вычислительных программ, использующих блок FPU, не ускорится в такой ситуации: ведь как бы мы не старались, модуль FPU у нас один и потому два задания одновременно исполнить не сможет. Таким образом, исходя из сугубо логических построений, кажется разумным делать различные нити программы не пересекающимися по необходимым им ресурсам. И будет нам счастье!
Однако не все так просто. В реальности все может оказаться и наоборот: две нити с интенсивными вычислениями с плавающей точкой в режиме HT выполняются существенно быстрее, чем последовательно; в то время как поток, ожидающий данные из памяти, сильно тормозит своего соседа, с памятью вообще не работающего.
Почему так происходит?
Рассмотрим подробнее пример с цепочками FP операций (то же верно и для MMX и SSE), например, цикл с простыми итерациями. Вспомним, что каждая операция имеет фиксированное время исполнения (латентность). Допустим, это команда умножения, FP_MUL с латентностью 6 тактов. Запустив эту команду на исполнение, планировщик задержит все остальные команды, зависимые от ее результата, минимум на 6 тактов, хотя уже на следующем такте FPU готов принять новую команду FP_ADD. Если такой независимой команды в очереди нет (а есть только команды типа FP_MUL), следующий такт будет пропущен. Если же в очереди вообще не осталось независимых команд, блок FPU будет простаивать целых 5 тактов.
Вот эти "пустые" такты и использует для своих вычислений второй Hyper Threading поток, команды которого всегда независимы от результатов команд первого.
Конечно же, с помощью специальных приемов оптимизации (таких, как "раскрутка" циклов) среднее количество независимых операций в FP очереди может быть увеличено и для единственного потока. Однако, чтобы полностью занять работой FPU, необходимо иметь 5-6 независимых потоков команд с точным балансом FP_ADD:FP_MUL 50:50, к тому же обеспеченных кэшированными данными, что для большинства алгоритмов является очень нетривиальной задачей оптимизации.
Из этого простого примера можно сделать два несколько парадоксальных наблюдения:
1. Ресурсы исполнительных блоков NetBurst на первый взгляд представляются избыточными, и их нехватка не должна сильно влиять на эффективность Hyper Threading. Особенно показательно это для целочисленных fast ALU блоков, которые могут выполнять микроопераций больше (до четырех за такт), чем им успевает "скармливать" Trace cache (до трех за такт).
2. Максимальный выигрыш от Hyper Threading по сравнению с последовательным исполнением потоков можно получить на неоптимизированных приложениях. Оптимизация, повышающая IPC одного потока, приводит к уменьшению пользы Hyper Threading. Более того, если разделяемые ресурсы процессора, за которые конкурируют нити, не ограничиваются только исполнительными устройствами (кэш, очереди, буфера и пр.), то, начиная с определенного уровня оптимизации, Hyper Threading будет только вредить: два потока последовательно будут выполняться быстрее, чем в режиме Hyper Threading.
Но вернемся к описанию реализации Hyper Threading в Pentium 4.
Технология Hyper Threading сравнительно легко реализовывается в микроархитектуре NetBurst, благодаря таким специфическим чертам последней, как Trace cache. В самом деле, в традиционной архитектуре (такой, как Р6) декодер сильно связан с исполнительными устройствами. Чтобы исполнять два потока инструкций одновременно, их необходимо одновременно превращать в микрооперации, что труднодостижимо. Но хуже всего то, что их придется одновременно выбирать для обоих потоков, что, в связи с переменной длиной х86 инструкций, весьма небанальная задача.
Совсем иное дело в случае, если у нас есть Trace cache: у нас уже есть некоторое количество декодированных команд, которые принадлежат различным нитям программы (или различным программам). Соответственно, выбирать те микрооперации, которые соответствуют определенной нити, гораздо проще, достаточно только добавить к микрооперации служебный идентификатор, указывающий, к какой нити относится эта микрооперация. Тем более что исполнительное ядро оказывается сравнительно слабо связанным с декодером, и его работа напрямую от декодера не зависит (лишь бы в Trace cache содержалось достаточное количество уже декодированных инструкций).
Итак, два наших логических процессора работают на одном физическом ядре. Выше мы уже писали, что все ресурсы ядра будут делиться на две большие категории: "совместно используемые" и "делимые". К делимым ресурсам относятся очереди Fetch Queue, Uop Queue, Schedulers Queue: для каждого из логических процессоров глубина очереди становится меньше, поскольку часть ее емкости расходуется на второй процессор. То есть, данные ресурсы разделяются пополам между логическими процессорами. И, например, есть позиция в очереди, которая может быть занята только первым логическим процессором. А есть позиция, которая может быть занята только вторым. В случае же "совместно используемых" ресурсов вопрос об их распределении будет решаться по ситуации. Что, однако, не исключает наличия специальной системы, предотвращающей монопольный захват ресурса одним из логических процессоров. Для чего это нужно, вполне понятно: если у нас есть один быстрый, а другой медленный (или вовсе остановившийся) поток команд, то медленный потенциально способен забить все очереди, полностью блокировав исполнение второго потока.
Посему в отношении очередей необходимо придумать способ наиболее эффективно распределить их емкость между процессорами. Каким образом два потока могут поделить места в очереди UopQ (или в любой другой), количество мест в которой фиксировано? Есть всего два принципиально разных способа: либо конкурентный, когда каждый из потоков пытается отобрать у другого как можно больше ресурсов, либо фиксированное разделение (допустим, пополам). В первом случае не исключена ситуация, когда один поток сильно затормозит или вообще полностью вытеснит второй. Во втором случае, если поток микроопераций требует не ровно половину ресурсов, получаем неэффективное их использование: одному потоку ресурсов мало, у другого потока часть ресурсов простаивает.
В процессоре Pentium 4 для очередей используется фиксированное разделение: емкость очередей Fetch Queue, UopQ и Schedulers Queue для каждого из логических процессоров вдвое меньше, чем в рассмотренном ранее варианте с отсутствующей (отключенной) технологией Hyper Threading. Это несколько ухудшает скоростные показатели каждого из процессоров, но избавляет от гораздо более неприятной ситуации полной блокировки процессора одним из потоков. Таким образом, в этом месте ресурсы разделяются "по справедливости". Важное примечание: продвижение вперед микроопераций в очереди для каждого из логических процессоров происходит независимо.
Совместно используемыми в такой интерпретации являются все остальные ресурсы процессора: регистровый файл, планировщики, исполнительные устройства, кэши всех уровней, блоки загрузки. Здесь принцип конкурентный: "кто первый встал, того и тапки". То есть, используется разделение "по-братски". Разумеется, присутствует арбитраж: если оба логических процессора обратились одновременно к одному и тому же ресурсу, то арбитр назначает строгую очередность запросов.
Приведем схематическую версию конвейера с обозначением делимых ресурсов. Заметно, что делимыми являются, прежде всего, очереди микроопераций.

Здесь синим обозначены ресурсы одного логического процессора, серым
– другого
А теперь рассмотрим, как арбитраж выглядит в случае Trace cache. Trace cache представляет из себя 8-канальный частично-ассоциативный кэш, работающий по LRU алгоритму. В Trace cache уже предварительно декодированным микрооперациям сопоставлены два независимых массива "указателей следующей инструкции", по одному на каждый логический процессор. Благодаря этому каждый логический процессор точно знает, где находится следующая микрооперация, принадлежащая его потоку.
Оба логических процессора конкурируют за доступ к Trace cache каждый такт процессора. Если обращения произошли одновременно, то доступ к Trace cache предоставляется каждому из них строго по очереди, через такт. То есть первый такт доступ у первого процессора, второй – у второго, третий – опять у первого, и так далее. В случае, если один из потоков остановился (либо не имеет в Trace cache декодированных микроопераций для своего потока), второму потоку предоставляется полный и безраздельный доступ.
Похожая схема доступа используется и в том случае, если в Trace cache содержится "ссылка" на Microcode ROM. Арбитраж доступа к Microcode ROM происходит по тем же принципам, что и арбитраж доступа к Trace cache.
Если микрооперации, на которую указывает флаг next-instruction-pointer, не оказалось в Trace cache, необходимо выдать запрос в кэш второго уровня и, получив из него следующую х86 команду, декодировать ее в микрооперации. В процессе добычи следующей х86 инструкции нам необходимо превратить виртуальный адрес микрооперации, на которую указывает next-instruction-pointer, в физический адрес инструкции (поскольку кэш L2 работает именно с физической адресацией). Для этого используется так называемая таблица трансляции адресов (Instruction Translation Lookaside Buffer (ITLB)). Именно она, приняв запрос Trace cache, переводит виртуальный адрес инструкции в физический и выдает запрос в кэш второго уровня. В большинстве случаев необходимая команда в L2 cache присутствует. Она помещается в специальный буфер (streaming buffer) своего логического процессора (размер его 2 строки по 64 байта) и находится там до тех пор, пока не будет декодирована и передана в Trace cache.
У каждого логического процессора своя таблица ITLB, то есть этот блок был дублирован для поддержки технологии Hyper Threading (собственно, на приведенной в начале главы схеме процессора обозначена именно дополнительная таблица ITLB). Кроме того, каждый логический процессор содержит свой набор указателей next-instruction-pointer, благодаря которым и отслеживается процесс декодирования х86 команд.
Арбитраж между двумя логическими процессорами по части запросов в кэш происходит по принципу FIFO (первым обслуживается более ранний запрос, все запросы обслуживаются в порядке очередности).
Модуль предсказания переходов частично используется совместно, частично дублирован: буфер стека возврата дублирован, поскольку это небольшая по площади структура, да и адреса запроса/возврата необходимо предсказывать для каждого логического процессора отдельно. Буфер истории переходов также дублирован для каждого процессора, поскольку историю перехода необходимо отслеживать отдельно для каждого логического процессора. Тем не менее, глобальная таблица переходов – общая структура, но записи каждого перехода снабжены меткой идентификатора логического процессора.
Декодер инструкций обязан декодировать х86 команды для обоих потоков, несмотря на то, что в каждый момент времени может декодироваться только одна х86 инструкция (и, разумеется, только для одного логического процессора). Более того, перед переключением на обработку буфера второго логического процессора декодер может обработать несколько х86 инструкций. То есть размер "окна" декодирования для каждого из логических процессоров может быть больше одной команды, то есть переключение между логическими процессорами каждый такт является необязательным. Таким образом, стратегия совместного использования декодера отличается от стратегии совместного использования Trace cache. Точный размер "окна" нам неизвестен, но вполне логичным выглядит предположение, что размер "окна" определяется количеством х86 команд, которые помещаются в streaming buffer логического процессора. Такая организация избавляет декодер от необходимости переключаться между логическими процессорами каждый такт.
Достаточно существенные подробности необходимо сказать о разделении ресурсов внутри ядра процессора. Перейдем к back end-у, попутно приведя схему участка конвейера.

Некоторые обозначения на этом рисунке отличаются от ранее использованных
нами обозначений. Тем не менее, в остальном этот рисунок очень удобен для нас,
поэтому мы будем специально оговаривать те места, где обозначения отличаются
Как мы помним из предыдущей главы, внеочередное исполнение команд начинается на стадии schQ (на рисунке обозначена как Shed), а заканчивается на стадии Register (на рисунке Register Write). Итак, какие особенности у нас возникают здесь?
Диспетчер (Allocator, о нем уже шла речь в прошлой главе), один из ключевых элементов логики, распоряжается следующим количеством ресурсов: 126 записей в ROB (Reorder Buffer), 48 записей в load buffers и 24 записи в store buffers. Также в его распоряжении 128 целочисленных регистров и 128 регистров с плавающей точкой.
Для каждого логического процессора есть ограничение максимального количества ресурсов, доступных ему. Каждый логический процессор может занимать до 63 записей в ROB, до 24 записей в load buffers и до 12 записей в store buffers. Это ограничение необходимо для того, чтобы один логический процессор не мог полностью захватить все ресурсы.
В ситуации, когда в очереди Fetch Queue (внимание, на рисунке обозначена как Uop Queue!) присутствуют микрооперации обоих потоков, диспетчер будет переключаться между логическими процессорами каждый такт, выделяя соответствующие ресурсы поочередно.
Если же у одного из логических процессоров закончились какие-либо необходимые ему ресурсы (например, свободные записи в store buffer), то диспетчер сгенерирует для этого процессора сигнал "stall" и продолжит выделение ресурсов другому логическому процессору. В дополнение: если очередь Fetch Queue содержит микрооперации только одного логического процессора, то диспетчер будет пытаться выделить ресурсы этому логическому процессору каждый такт для максимизации производительности. При этом ограничения на максимально доступные логическому процессору ресурсы остаются, во избежание блокировки процессора одним из потоков.
Еще одним из продублированных ресурсов, обозначенных на схеме в начале этой главы, является таблица отображения регистров (Register Alias Table, RAT). Ее задача состоит в отображении 8 архитектурных регистров на 128 физических. У каждого логического процессора есть своя RAT, при этом ее данные являются неотъемлемой частью архитектурного состояния логического процессора.
Планировщики, сердце системы внеочередного исполнения команд, работают с логическими процессорами несколько особым образом. Для них нет существенной разницы, к какому логическому процессору относятся те или иные микрооперации. Например, за один такт планировщики могут отправить на исполнение в сумме до шести микроопераций. Это могут быть по две микрооперации от каждого логического процессора, либо три от одного процессора и одна от другого. Правда, существует ограничение: все места в очереди schQ заданного планировщика не могут принадлежать одному логическому процессору, во избежание захвата ресурсов и блокирования второго логического процессора.
Исполнительные устройства и подсистема памяти используются логическими процессорами совместно и без особых ограничений. Эти блоки не обращают внимания на "принадлежность" микроопераций к тому или иному логическому процессору.
Такая структура, как DTLB (таблица трансляции виртуальных адресов в физические, но уже для данных), используется совместно. Каждая запись в ней снабжена меткой идентификатора логического процессора.
Кэши всех иерархий используются логическими процессорами совместно; никаких ограничений на их использование нет, принадлежность запросов тому или иному логическому процессору не отслеживается.
Разумеется, разделение ресурсов влечет за собой некоторые подводные камни. Как мы видели выше, конкурентная борьба двух логических процессоров за разделяемые ресурсы приводит к тому, что доступный каждому потоку набор ресурсов меньше, чем в случае работы только одного потока. В частности, кэш данных первого уровня у ядра Northwood и без того не блещет размером, всего 8КВ. При применении технологии Hyper Threading эффективный размер кэша для каждого из потоков становится примерно вдвое меньше, 4КВ. Кстати, такая формулировка заставляет задуматься вот над чем: весьма вероятно, что существующее увеличение эффективности технологии Hyper Threading в ядре Prescott связано как с усовершенствованием этой технологии, так и с тем банальным фактом, что кэш первого уровня вдвое увеличился в размере. Что, в свою очередь, несколько уменьшило потери производительности от его дефицита.
Авторам подобная идея кажется вполне логичной и имеющей право на жизнь.
В любом случае, наличие двух потоков в общем случае все же снижает скорость обработки каждого из них. В частности, время исполнения основного потока в присутствии фонового увеличивается. Тем не менее, в большинстве случаев совместное время исполнения обоих потоков все же меньше, чем сумма времен исполнения каждого из них. Говоря проще, наличие второго потока все-таки притормаживает первый, но обычно производительность все же растет, поскольку оба потока исполняются меньше времени, чем понадобилось бы, исполняй мы их по очереди.
Немаловажным в вопросе использования технологии Hyper Threading является оптимизация программного обеспечения. В самом деле, если активный поток создаст запрос к памяти и не освободит при этом исполнительные устройства, то второй поток не сможет продолжить работу, а первый – не имеет для продолжения необходимых данных. Более того, в однопоточной системе достаточно исчерпать емкость очереди одного-единственного планировщика, чтобы на остальные планировщики, даже ничем не занятые при этом, не попало ни единой команды. Именно поэтому качество оптимизации кода становится основополагающим критерием эффективности работы этой технологии.
Кроме всего прочего, для нормальной работы необходима операционная система, умеющая корректно работать с технологией Hyper Threading. Подходящими по характеристикам в семействе Windows является Windows XP (и более поздние операционные системы). Более ранние операционные системы (например, Windows 2000) не умеют отличать физические процессоры от логических, хотя принципиально работать на таких системах способны.
Подытожим: технология Hyper Threading базируется на идее более эффективно использовать блоки процессора, "разделив" их между отдельными логическими процессорами и снижая их простой. Прирост от применения технологии Hyper Threading находится в диапазоне от 0% до 30%, в отдельных случаях возможно некоторое падение производительности. Эффективность технологии Hyper Threading находится в сильной зависимости от качества оптимизации программного обеспечения под эту технологию. Технология Hyper Threading не способна заменить настоящую двухпроцессорную систему, но и затраты на Hyper Threading со стороны покупателя невелики (по сути, никаких дополнительных затрат покупатель не несет, а увеличение площади процессора невелико).
С точки зрения технологов, внедрение технологии Hyper Threading не слишком сложно, добавляется менее пяти процентов транзисторов. Однако работа обслуживающей процессор логики сильно усложняется. Более того, нельзя исключать, что без технологии Hyper Threading процессор выглядел бы совсем другим образом.
В целом, технологию Hyper Threading для микроархитектуры NetBurst следует признать скорее полезной, нежели вредной. В большинстве ситуаций она все же подымает производительность, а это и есть основной критерий полезности любого нововведения.
Далее: Prescott: Последний из могикан? (Pentium 4: от Willamette до Prescott). Часть 4



{kind=link}
© 1998-2023 fcenter.ru | Россия
© 1998-2023 fcenter.ru | Россия