Ваш город: Москва
Intel Prescott: в погоне за частотой
Введение
После относительного затишья на процессорном рынке началась горячая пора. Минувшей осенью компания AMD совершила мощный рывок и представила свою новую процессорную архитектуру Athlon 64. С выходом процессоров Athlon 64 и Athlon 64 FX конкуренция среди CPU для настольных PC возобновилась с новой силой. Действительно, в отличие от своих предшественников, Athlon XP, эти процессоры показывали более высокую производительность, нежели старшие модели в линейке Pentium 4 от Intel. Не спасало положение и появление процессора Pentium 4 Extreme Edition, оснащенного кеш-памятью третьего уровня: все портила заоблачная цена и недоступность (во всех смыслах) данного процессора. Обстановка начала накаляться. Некоторые аналитики даже начали проводить параллели с ситуацией 1999 года, когда выход первых процессоров AMD Athlon застал Intel явно врасплох. Однако сегодняшнее положение все же значительно отличается от того. В запасе у Intel имелся неразыгранный козырь – новое процессорное ядро Prescott, сроки выхода которого хотя и были несколько отодвинуты, но не настолько, чтобы за это время архитектура Athlon 64 успела бы серьезно укрепиться на рынке.
Сегодня Intel официально объявляет о выпуске первых процессоров, основанных на ядре Prescott. Таким образом, мы становимся свидетелями очередного витка процессорной "гонки вооружений", а именно начала соперничества новых микроархитектур Athlon 64 от AMD и Prescott от Intel. Впрочем, при этом не следует забывать, что и у AMD остались в кармане нереализованные козыри. В частности, процессоры Athlon 64 поддерживают технологию x86-64, которая пока не задействуется современным программным обеспечением. Что же касается наличия 64-битных расширений в Prescott, то их в этом процессоре нет (или же Intel пока не считает нужным показывать их общественности). Однако, вопрос о необходимости поддержки 64-битности современными процессорами для настольных PC скорее философский, и он будет оставаться таковым по меньшей мере до появления 64-битных версий Windows XP. Сегодня же соперничество AMD и Intel вновь будет происходить на 32-битном поле.
В данном материале мы решили подробно остановиться на основных архитектурных особенностях ядра Prescott и его отличиях от предшественников, ибо сказать на эту тему можно немало. И, прежде чем перейти непосредственно к обсуждению новинки от Intel, позволим себе для внесения окончательной ясности четко сформулировать, что же Intel проанонсировала сегодня.
Итак, сегодня, 2 февраля 2004 года корпорация Intel объявила о выпуске и начале продаж новых процессоров, известных ранее под кодовым именем Prescott. Эти процессоры, обладая новым ядром, производимым по 90-нанометровой технологии нового поколения, будут продолжать линейку Pentium 4 по меньшей мере в течение ближайшего года, постепенно вытесняя предшествующее 130 нм ядро, Northwood. Объявленные сегодня процессоры Pentium 4 на ядре Prescott имеют тактовые частоты от 2.8 до 3.4 ГГц, предназначаются для использования в Socket 478 материнских платах с 800-мегагерцовой шиной и поддерживают технологию Hyper-Threading. Переходим к подробностям.
90 нм технологический процесс
Прежде чем углубиться в описание архитектурных особенностей новых процессоров Pentium 4, известных также под кодовым именем Prescott, отдельно следует остановиться на новом технологическом процессе, используемым для создания этих CPU. Дело в том, что Prescott стал первым серийно выпускаемым x86 процессором, для производства которого используется техпроцесс с проектной нормой 90 нм. Например, компания AMD, являющаяся основным конкурентом Intel, планирует осуществить переход на 90 нм технологию только во второй половине этого года.
К настоящему времени свой 90 нм техпроцесс Intel ввела уже на трех фабриках, поэтому с массовым производством кристаллов с использованием этого процесса проблем быть не должно. Следует заметить, что вместе с переходом на новые проектные нормы Intel также внедрила в техпроцесс и ряд усовершенствований, которые должны сказаться на увеличении быстродействия транзисторов, что в конечном итоге выльется в возможность дальнейшего наращивания тактовых частот процессоров, изготовленных на новом технологическом процессе. Среди этих усовершенствований в первую очередь следует выделить уменьшение величины затвора и применение "растянутой" кремниевой решетки.

Транзисторы, которые Intel применяет в процессорах, производимых по 130-нанометровой технологии, имеют длину затвора 60 нм. При переходе на 90 нм технологию длина затвора в транзисторах уменьшилась до 50 нм. Таким образом решатся сразу две задачи. Во-первых, увеличивается скорость срабатывания транзистора. А во-вторых, уменьшаются физические размеры транзистора, что позволяет создание более компактных и одновременно более сложных полупроводниковых устройств. Впрочем, у уменьшения размера транзисторов есть и оборотная сторона: увеличение токов утечки, с которыми при использовании 90-нанометрового техпроцесса приходится бороться особо. Например, для их минимизации Intel перешла на использования слоя силицида никеля над электродом затвора (ранее для этой цели применялся силицид кобальта).
Но наиболее интересная часть 90 нм техпроцесса от Intel – это все же примененная технология "растянутого" (напряженного) кремния, разработанная для того, чтобы в открытом состоянии транзисторы могли пропускать больший ток, а, следовательно, и быстрее срабатывать, выделяя при этом меньшее количество тепла. Согласно данным Intel, благодаря применению этой технологии ток через канал транзистора в открытом состоянии возрастает на 10-20%. Суть технологии проста – кристаллическая решетка кремния, примененная в канале транзистора "растягивается" таким образом, чтобы атомы разошлись на большее расстояние. Достигается это помещением кремния на специальную подложку с более широкой кристаллической решеткой. Подстраиваясь под кристаллическую решетку подложки, атомы кремния "раздвигаются" на большее расстояние друг от друга. В результате, сопротивление движению электронов через кристаллическую решетку уменьшается. Несмотря на кажущуюся сложность процесса получения "растянутого" кремния, технология эта отнюдь не дорогая: стоимость изготовления транзисторов, в которых применяется "растянутый" кремний, возрастает по сравнению с обычными всего лишь на 2%.
Следует также заметить, что помимо перечисленных, появились в 90 нм техпроцессе от Intel и еще кое-какие, менее кардинальные изменения. В частности, Intel начала использовать новый Low-k диэлектрик CDO (Carbon-doped Oxide) для изоляции медных соединений с коэффициентом диэлектрической проницаемости 2.9. Использование CDO позволяет уменьшить уровень паразитных емкостных связей на 18 процентов по сравнению с применяемым сейчас диэлектриком SiOF. Помимо этого в 90 нм полупроводниковых кристаллах возросло число слоев металлических (медных) проводников: например, в Prescott количество слоев медных соединений достигло семи, в то время как процессоры Northwood содержали только шесть слоев металлизации. Данное нововведение обеспечивает большую гибкость при создании комплексных полупроводниковых устройств и позволяет разместить большее число транзисторов на кристалле меньшей площади. Впрочем, в этом ничего революционного нет: процессоры AMD Athlon 64, например, содержат девять слоев медных проводников.
Следует заметить, что переход на новый технологический процесс Intel удалось провести "малой кровью". Новое литографическое оборудование с длиной волны 193 нм используется при изготовлении 90 нм полупроводниковых кристаллов только лишь для критических участков чипа, в остальных случаях Intel обходится применением старой 248-нанометровой литографии с применением фазосдвигающих масок. Именно поэтому Intel заменила на заводах, производящих 90 нм кристаллы, лишь порядка 25% оборудования. Что же касается тотальной смены литографического оборудования, то Intel планирует проводить ее только при внедрении 65-нанометровой технологии.
Ядро Prescott
Ядро Prescott существенно отличается от предыдущих процессорных ядер, используемых в процессорах Pentium 4. Говорить о том, что новое ядро представляет собой Northwood c увеличенной кеш-памятью, переведенный на новый технологический процесс, было бы совершенно неправильно. Отличия Prescott лежат гораздо глубже. За примерами ходить далеко не надо, достаточно просто взглянуть на фотографию процессорного ядра Prescott:

При создании Prescott многие функциональные блоки были спроектированы инженерами заново. Плюс при создании этого ядра более активно использовались методы компьютерного моделирования. Результатом такого подхода стало то, что вид ядра Prescott сильно отличается от того, как выглядят другие ядра. На фотографии мы не можем четко выделить отдельные функциональные блоки. Многие части процессора оказались просто "размазаны" по ядру. Дело в том, что расположение транзисторов в Prescott на этапе проектирования оптимизировалось с тем, чтобы обеспечить лучшие возможности по увеличению тактовой частоты, минимизировать задержки при распространении сигналов и равномерно распределить тепловыделение по площади кристалла. В результате, например, явление локального перегрева отдельных функциональных блоков будет присуще Prescott гораздо в меньшей мере, чем другим процессорным ядрам. Таким образом, от старой схемы проектирования процессоров, когда функциональные блоки процессора создавались отдельно, а потом объединялись в общий кристалл, Intel отказалась.
Что же касается базовых характеристик ядра Prescott, то они приведены в таблице ниже:
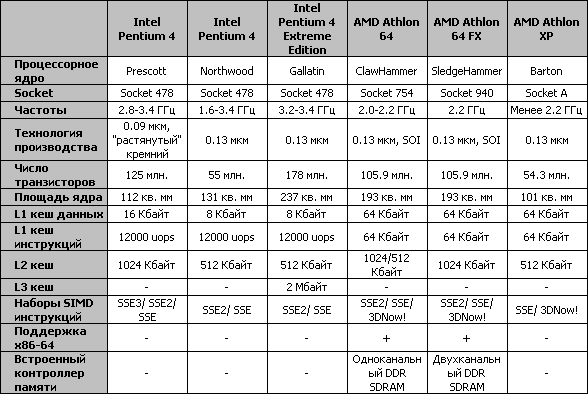
Как видим, число транзисторов в Prescott возросло по сравнению с Northwood более чем вдвое. Однако заслуга в этом лежит явно не на увеличившимся вдвое кеше второго уровня, поскольку L2 кеш в Prescott занимает только примерно 25% площади ядра. Также вряд ли такое количество транзисторов могло уйти на реализацию увеличенного кеша данных первого уровня или на поддержку нового набора команд SSE3, состоящего из тринадцати инструкций. Значит, дополнительные транзисторы появились в Prescott и по многим другим причинам. Давайте попробуем понять, по каким.
Конвейер Prescott
Как и предшествующие ядра Willamette и Northwood, новое ядро Prescott основывается на микроархитектуре NetBurst, введенной Intel с выходом первых Pentium 4. Основная идея данной архитектуры – достижение высокой производительности CPU путем наращивания тактовой частоты. Ни для кого не является секретом, что тактовая частота процессоров Pentium 4 в сравнении с частотой других процессоров выглядит чрезвычайно впечатляюще. В Prescott данная идея получила дальнейшее развитие: Intel внесла определенные изменения в это ядро, позволяющие совершить новый рывок в тактовых частотах. Помимо полупроводниковых технологий, "растянутого" кремния и специального автоматизированного проектирования дизайна ядра, изменения коснулись и собственно микроархитектуры. Intel даже упоминает о том, что в основе Prescott лежит "усовершенствованная микроархитектура NetBurst".
Очевидно, что ключом к покорению процессором высоких частот лежит удлинение исполнительного конвейера. В этом случае исполнение команд разбивается на более простые стадии, что позволяет уменьшить время их выполнения, то есть увеличить частоту подачи команд на конвейер. Выпустив процессоры семейства Pentium 4, Intel увеличила длину конвейера с 10 стадий в Pentium III до 20 стадий в Pentium 4. Эффект такого изменения мы наблюдаем и по сей день: если максимальная частота Pentium III так и не перевалила через 1.5 ГГц, то сегодняшние процессоры Pentium 4 без всяких проблем работают на частотах свыше 3 ГГц. Желая продолжить начатое дело, в Prescott конвейер был удлинен еще в большей степени.
Благодаря этому, Intel надеется, что процессоры с ядром Prescott смогут покорить частоты порядка 4.5 ГГц. Очевидно, что для достижения этой цели конвейер процессора должен быть увеличен весьма значительно. Сама Intel не раскрывает конкретных данных относительно реальной длины конвейера в Prescott. Однако подтверждает, что число этих стадий стало не менее 30.
Более того, проведенное нами эмпирическое вычисление длины конвейера Prescott, основанное на оценивании времени, затрачиваемого процессором на перезаполнение конвейера при неправильно предсказанном переходе, показало, что реальная длина конвейера в Prescott и вовсе составляет порядка 35-36 стадий.
В то же время не следует забывать, что медаль под названием "удлинение конвейера и рост тактовой частоты" имеет и обратную сторону. Во-первых, с увеличением частоты процессора более ощутимыми становятся простои ядра, вызванные отсутствием в кеше необходимых для работы данных. Поскольку скорость подсистемы памяти в современных платформах крайне низка по сравнению со скоростью вычислительных устройств процессора, часть которых (два из трех ALU), кстати, в процессорах NetBurst архитектуры работает к тому же на удвоенной частоте ядра, простои процессора, вызванные отсутствием в сфере досягаемости данных для обработки, оказываются просто катастрофическими. Во-вторых, длинный конвейер становится большой проблемой и при неправильном предсказании условных переходов: в этом случае высокий темп работы исполнительных устройств нарушается, и процессор вынужден сбрасывать весь конвейер, а затем заполнять его заново, на что, при более длинном конвейере, естественно, затрачивается продолжительное время.
Две указанные проблемы длинного конвейера и обозначили два основных направления работы, на которых сосредоточились инженеры Intel. Влияние именно этих негативных факторов длинного конвейера Prescott необходимо было ликвидировать для того, чтобы конечная производительность Prescott не стала провальной характеристикой этого процессора сейчас, когда достижение ощутимо более высоких частот, чем у Pentium 4 предыдущего поколения, остается невозможным в силу неотлаженности технологического процесса.
Не останавливаясь на описании NetBurst архитектуры, мы проследим, какие же улучшения произошли в ядре Prescott по сравнению с предшествующим ядром Northwood.
Усовершенствования в микроархитектуре
С выходом ядра Prescott Intel совершила наиболее значительный шаг на пути улучшения микроархитектуры NetBurst. На иллюстрации ниже приведено своего рода генеалогическое дерево NetBurst, на котором выделены усовершенствования, присутствующие в Prescott.

Остановимся на сути этих усовершенствований более подробно.
Улучшенное предсказание ветвлений
Самый главный метод борьбы с простоями процессора, вызванными необходимостью очистки и перезаполнения длинного конвейера Prescott после неправильно предсказанных переходов состоит в том, чтобы не допускать эти самые неправильные предсказания переходов. Хотя существующая в классическом NetBurst схема предсказания переходов давала очень неплохие результаты, Intel смогла еще дополнительно увеличить ее эффективность.
Работа блока предсказания переходов, применяющегося в процессорах с NetBurst архитектурой, основывается на работе с Branch Target Buffer (BTB), 4-килобайтном буфере, в котором накапливается статистика выполненных переходов. Иными словами, для предсказания переходов используется вероятностная модель - преимущественным направлением перехода процессор считает то направление, которое является наиболее вероятным согласно собранным статистическим данным. Данный алгоритм очень неплохо показывает себя в деле, однако он оказывается совершенно бесполезен в том случае, если по конкретному переходу статистика еще не накоплена. Процессоры на ядре Northwood в этом случае всегда выбирали направление перехода "назад", считая, что самые распространенные переходы – это условия выхода из циклов.
В Prescott эта статическая схема предсказания переходов была существенно доработана. Теперь, если по встретившемуся переходу статистика отсутствует, модуль предсказания перехода не делает однозначного вывода о его направлении, а основывает свое решение на анализе расстояния, на которое совершается переход, поскольку обратные переходы в циклах редко совершаются на расстояния, превышающую некую эмпирически найденную границу.
Кроме того, несколько была усовершенствована и схема динамического предсказания переходов. В процессор Prescott был добавлен блок косвенного предсказания переходов (indirect branch predictor), который впервые нашел свое применение в CPU семейства Pentium M и хорошо зарекомендовал себя там.
В результате, если у процессоров на ядре Northwood число неправильно предсказанных переходов составляло в среднем 0.86 на 100 инструкций, то теперь эта величина понизилась до 0.75 неправильных переходов на 100 инструкций. То есть, другими словами, мы имеем на 12% меньше неправильно предсказанных переходов, что выливается в гораздо меньшие простои процессора, вызванные необходимостью очистки и перезаполнения конвейера.
Ускорение исполнение команд
Несмотря на то, что количество целочисленных ALU в процессоре осталось тем же: два, работающих на удвоенной частоте ядра, для простых инструкций плюс еще одно для сложных инструкций, скорость исполнения отдельных команд в Prescott возросла. Объясняется это некоторыми изменениями, внесенными в ALU.
В первую очередь отметим, что в одно из быстрых ALU был добавлен блок shifter/rotator, исполняющий инструкции типа сдвига и вращения. Благодаря этому такие инструкции теперь исполняются гораздо быстрее, поскольку в предыдущих реализациях Pentium 4 сдвиг и вращение трактовались как сложные инструкции и выполнялись на медленном ALU.
Также, гораздо быстрее в процессорах на ядре Prescott будет выполняться и операция целочисленного умножения. В предыдущих реализациях NetBurst целочисленное умножение выполнялось на блоке FPU с предварительным переводом операндов сначала в формат с плавающей точкой, а потом обратно. В Prescott же операции целочисленного умножения стали выполняться целочисленным ALU, что естественно, ощутимо снизило время их выполнения.
Измерения показывают, что в результате указанных изменений скорость выполнения сдвигов и вращений возросла по меньшей мере в четыре раза, а целочисленные умножения стали выполняться на 25% быстрее. Впрочем, при этом надо иметь в виду, что из-за увеличения длины конвейера и изменения алгоритмов работы кеша первого уровня задержки, возникающие при исполнении других простых команд, несколько возросли. Многие команды, на выполнение которых ранее тратилось не более полтакта, теперь вызывают задержки в целый такт, поэтому говорить о том, что скорость ALU в целом возросла, было бы неправильно.
Улучшенная предварительная выборка данных
Данное усовершенствование призвано уменьшить проблему с отсутствием в кеше процессора данных для обработки – достаточно неприятную ситуацию, вызывающую простои процессора в ожидании получения данных из памяти. Помимо того, что в Prescott просто вдвое возросли объемы кеш-памяти данных первого и второго уровней, Intel улучшила алгоритмы предварительной выборки данных.
Данные усовершенствования затрагивают как программную предвыборку, инициируемую работающей программой, так и аппаратную предвыборку. Что касается программной предвыборки, то теперь инструкции выборки обрабатываются процессором даже в том случае, если сведения о запрашиваемых данных отсутствуют в TLB, а, кроме того, эти инструкции могут кешироваться в Trace Cache. Впрочем, толку от этого не так уж и много, существующие компиляторы инструкции предварительной выборки в коде не расставляют, а потому гораздо большее значение имеет улучшение аппаратной предвыборки. По данным Intel, новый алгоритм аппаратной выборки, примененный в Prescott и отслеживающий потоки, как данных, так и кода, обеспечивает достаточно весомый прирост в производительности процессора, оцениваемый величиной в 35%.
К перечисленным изменениям следует добавить также и увеличение количества WC (write combining) буферов, в конечном итоге приводящее к возможности одновременного исполнения большего числа инструкций типа сохранения или загрузки данных.
На рисунке ниже приведена блок-схема процессора Prescott:

Собственно, эта блок схема показывает, что структурных изменений в Prescott по сравнению с предшествующими процессорами NetBurst архитектуры не произошло. Самые явные отличия – изменившиеся размеры и организация L1 и L2 кеша, о которых мы поговорим несколько подробнее ниже.
Кеш и подсистема памяти
Кеш-память – это, пожалуй, самое сильно изменившееся место в Prescott. По крайней мере, различия в размерах кеш-памяти Prescott и Northwood относятся именно к тем отличиям этих ядер, которые заметны невооруженным взглядом. Размер кеша данных первого уровня в Prescott увеличился с 8 до 16 Кбайт, кеш второго уровня вырос с 512 Кбайт до 1 Мбайта. Что касается организации кеш-памяти в Prescott, то L1 кеш данных - ассоциативный 8-областной с длиной строки 64 байта. Алгоритм работы этого кеша– WriteThrough. То есть, по сравнению с Northwood число областей ассоциативности L1 кеша выросло вдвое. Кеш второго уровня в Prescott по своей организации от кеша Northwood не отличается: он также восьмиканальный, использует WriteBack алгоритм и содержит строки длиной 128 байт. Шина кеша L2 в Prescott 256-битная и в этой части мы вновь не видим никаких отличий от Northwood.
Теоретически, увеличение объемов кеш-памяти – это еще один метод борьбы с простоями процессоров, вызванными ожиданием данных для обработки. Поэтому, с ростом тактовых частот процессоров и увеличением разрыва между скоростью CPU и скоростью памяти значение кеш-памяти для данных будет только усиливаться. Таким образом, расширение L1 и L2 кеша – чрезвычайно важный шаг в Prescott, особенно учитывая то, что это ядро разрабатывалось с прицелом на значительное возрастание тактовой частоты.
Что же касается кеша первого уровня для инструкций, называемого в архитектуре NetBurst Execution Trace Cache за то, что хранит он цепочки инструкций в уже декодированном виде, то его организация и размер остался неизменным – он способен вместить до 12000 микроопераций, что эквивалентно объему в 8-16 Килобайт.
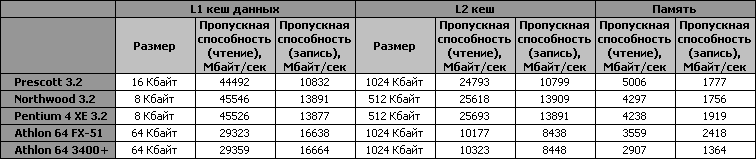
Впрочем, давайте посмотрим на реальную скорость работы кеш-памяти в Prescott, тем более что тут нас поджидают новые сюрпризы. Для измерений скорости и латентности кеша и памяти мы пользовались утилитой Cache Burst 32. Тестовая система, на которой мы проводили измерения, основывалась на материнской плате ASUS P4C800-E Deluxe на чипсете i875P и была снабжена двухканальной DDR400 SDRAM с таймингами 2-3-2-6. Для опытов мы использовали процессоры Pentium 4 на ядре Northwood, Pentium 4 на ядре Prescott и Pentium 4 Extreme Edition, работающие на частоте 3.2 ГГц. Для сравнения мы использовали и платформы, основанные на процессорах Athlon 64. Одна система использовала процессор Athlon 64 FX-51 с частотой 2.2 ГГц и двухканальную регистровую DDR400 SDRAM с таймингами 2-3-2-6, а вторая – основывалась на процессоре Athlon 64 3400+ с частотой 2.2 ГГц и была снабжена DDR400 памятью с аналогичными таймингами. Остальные составляющие тестовых систем на результатах наших экспериментов не сказываются, поэтому позволим себе опустить их описание.
В первую очередь мы измерили пропускную способность подсистем памяти, получаемую в платформах, основанных на различных CPU. На графиках ниже мы сравнили скорость работы памяти в системах на базе Pentium 4 (Prescott), Pentium 4 (Northwood) и Pentium 4 Extreme Edition при работе с блоками различного размера.



Впрочем, то, что мы видим на графиках – просто красивые картинки, годящиеся только лишь для качественного анализа. Для более грамотных выводов мы воспользуемся цифрами, к которым добавим результаты, измеренные нами в системах на базе процессоров AMD.
Нажмите для увеличения
Как видим, вместе с увеличением объема кеша первого уровня в Prescott по сравнению с Northwood наблюдается некоторое падение его пропускной способности. Аналогичная картина наблюдается и при измерении пропускной способности кеша второго уровня. Впрочем, при сравнении пропускных способностей кеш-памяти у процессоров семейства Pentium 4 и Athlon 64 первые явно остаются в выигрыше благодаря более широкой шине, соединяющей кеш второго уровня с ядром.
Отметим одну любопытную деталь. Притом, что скорость чтения и записи при работе с кеш-памятью Prescott не превышает соответствующие скорости, измеренные у Northwood, скорость копирования данных у 90 нанометрового процессора значительно превосходит эту характеристику ядра Northwood. Объясняется данный эффект тем, что ядро Prescott помимо всего прочего содержит дополнительные усовершенствования процедур сохранения и загрузки данных, позволяющие процессору использовать предварительно сохраняемые данные еще до того, как они запишутся в кеш благодаря наличию специального Store Forwarding Buffer.
При измерении скорости работы с памятью нас ждет весьма неожиданный сюрприз. Prescott показывает большую, чем Northwood, скорость при чтении данных из памяти. Этот вполне осязаемый результат является итогом применения в новом процессорном ядре улучшенной предварительной выборки данных, о чем мы говорили выше.
Помимо пропускной способности для нас важна и другая характеристика подсистемы памяти и кешей, а именно их латентность.

К сожалению, даже беглого взгляда на график достаточно, чтобы понять, что латентность L1 и L2 кеша в Prescott значительно возросла по сравнению с предыдущим ядром, Northwood. А вот и конкретные цифры:

Нажмите для увеличения
Да, к сожалению, мы должны констатировать, что вместе с увеличением объема кеш-памяти в Prescott выросла и ее латентность. Причем, рост этот достаточно значительный – в два раза, например, для кеша первого уровня. В результате теперь Intel не сможет хвастаться экстремально низкой латентностью своего кеша данных первого уровня. Во временном измерении латентность L1 кеша данных новых Pentium 4 вплотную приблизилась к латентности L1 кеша процессоров Athlon 64, который, к слову, имеет вчетверо больший объем. Впрочем, увеличение латентности L1 кеша – это еще один необходимый шаг для достижения процессорами Prescott частот свыше 4 ГГц.
Аналогичные изменения произошли с кешем второго уровня. По латентности L2 кеша новый процессор Prescott уступает как предшественнику с ядром Northwood, так и конкурирующим CPU семейства AMD Athlon 64.
Хотя теоретически латентность памяти измениться в Prescott не должна была, на деле и в этом случае наблюдается некоторое ухудшение латентности.
В итоге, остается только признать, что в погоне за перспективой дальнейшего увеличения тактовой частоты, латентности Prescott при работе с данными значительно возросли. Однако с другой стороны не следует забывать и о том, что вместе с этим Intel применила в новом ядре ряд методик, позволяющих использовать шины памяти более эффективно, и это мы смогли реально увидеть по возросшей пропускной способности при копировании данных и по возрастанию скорости чтения данных из памяти.
Технология Hyper-Threading
О том, что технология Hyper-Threading в процессорах на ядре Prescott будет подвергнута некоторым улучшениям, говорилось давно. Некоторые ожидали, что Prescott сможет представляться операционной системе четырьмя логическими процессорами, другие считали, что Prescott будет лучше разбираться с ситуациями, когда один поток блокирует исполнение другого. Однако на деле не произошло ни того, ни этого.
Процессор Pentium 4 на базе ядра Prescott представляется в операционной системе двумя логическими процессорами, а блокировка потоков, как мы убедились в практических экспериментах, точно также может тормозить работу этого процессора при включенной технологии Hyper-Threading.
Несколько подробнее расскажем про суть проведенного нами эксперимента. Для целей практического исследования Hyper-Threading в Prescott была написана небольшая программка, создающая в системе два потока. Первый поток просто складывает целые числа и по окончании своей работы выставляет флаг завершения. Второй поток представляет собой пустой spin-wait цикл, выход из которого осуществляется при выставлении первым потоком флага об окончании работы.
На процессорах с ядром Northwood и поддержкой технологии Hyper-Threading выполнение этой простой программы приводит к достаточно плачевным для производительности последствиям. Пустой цикл блокирует исполнительные устройства процессора, в результате чего скорость исполнения первого реального вычислительного потока резко падает.
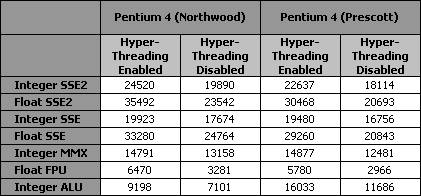
Не разводя лишней демагогии, просто приведем результаты. Для начала, вот что было получено на Pentium 4 (Northwood) с частотой 3.2 ГГц при включении и выключении технологии Hyper-Threading:


Northwood, HT enabledNorthwood, HT disabled
Первое число, которое выводит наш тест – время исполнения вычислительного потока, запущенного в одиночку. Второе число – время работы, когда в параллели с вычислительным потоком запущен второй поток - пустой spin-wait цикл. Как мы видим, в этом случае технология Hyper-Threading сильно вредит производительности. Время выполнения теста при включении технологии Hyper-Threading возрастает в 2.5 раза: пустой цикл блокирует исполнительные устройства процессора, не давая возможности для работы первого потока. Несмотря на то, что наш тест носит явно синтетический характер, подобные ситуации возникают и при работе реальных многопоточных приложений. Именно такими эффектами, которые мы смоделировали в нашем случае, и объясняются факты, когда Hyper-Threading снижает производительность.
Третье и четвертое числа, выдаваемые нашим тестом, показывают время выполнения двух потоков, но при использовании различных оптимизаций предупреждающих явление блокировки одного потока другим. В одном случае мы пользовались командой PAUSE, а в другом – использовали специальный объект синхронизации операционной системы Windows.
Посмотрим теперь, как отреагирует на наш коварный тест процессор с ядром Prescott:


Prescott, HT enabledPrescott, HT disabled
Как видим, принципиально ничего не меняется. Аналогично предыдущим результатам, наш тест выявляет те же самые недостатки технологии Hyper-Threading, которые мы видели и в Northwood.
Однако кое-какие улучшения технологии Hyper-Threading в Prescott все же действительно были сделаны. Во-первых, введенный в 90 нм ядро набор инструкций SSE3, о котором мы еще поговорим несколько ниже, предоставляет в распоряжение программистам новые возможности для синхронизации потоков. Кроме того, Prescott научился распараллеливать некоторые процессы, которые в Northwood могли выполняться только по одному. Не вдаваясь в подробности, отметим, что в первую очередь это касается одновременной работы потоков с кеш-памятью.
Набор инструкций SSE3
Еще одним нововведением в ядре Prescott стало добавление нового набора SIMD инструкций, известного изначально под названием PNI (Prescott New Instructions), но получившего маркетинговое имя SSE3. Впрочем, тот набор новых команд, который включает в себя SSE3, полноценным назвать вряд ли получится. SSE3 включает всего 13 новых инструкций, что выглядит несколько несерьезно по сравнению с предыдущими SIMD наборами от Intel, состоящими из нескольких десятков новых команд. Да и по сути SSE3 – это вовсе не новое подмножество инструкций, предназначенных для каких-то конкретных задач. Это просто несколько дополнений к уже имеющимся наборам командам, представляющих собой скорее "работу над ошибками".
Набор SSE3 включает в себя следующие новые инструкции:
HADDPS, HSUBPS, HADDPD, HSUBPD - горизонтальные операции с SSE2 регистрами, почему-то забытые при разработке набора инструкций SSE2. Данные команды могут быть чрезвычайно полезны при обработке 3D графики, так как позволяют упростить вычисление такой распространенной величины, как скалярного произведения векторов.
ADDSUBPS, ADDSUBPD, MOVSHDUP, MOVSLDUP, MOVDDUP – инструкции для работы с комплексными числами. Данные команды могут оказаться полезными при расчете волновых процессов и работе со звуком, в общем там, где применятся быстрое дискретное преобразование Фурье.
FISTTP – новая инструкция арифметического сопроцессора, позволяющая преобразование стека сопроцессора к целому типу. Данная операция по каким-то непонятным причинам в системе команд x87 ранее отсутствовала.
LDDQU – инструкция для загрузки 128-битных невыровненных данных. Может оказаться полезной для ускорения процесса сжатия видео.
MONITOR, MWAIT – команды для оптимизации многопотоковых программ. Данные инструкции позволят достичь большей производительности в системах с технологией Hyper-Threading и избежать описанных выше проблем с блокировкой потоками друг-друга.
Хотя Intel выпустила руководство по использованию SSE3 инструкций для программистов еще летом прошлого года, программ, в которых новые команды использовались бы, на сегодняшний день нет. Впрочем, уже совершенно точно известно, что они появятся в самом ближайшем будущем. В первую очередь, SSE3 инструкции начнут применяться в различных видеокодеках, поскольку, согласно данным Intel, применение в алгоритмах кодирования инструкции LDDQU может внести в процесс сжатия видео ускорение до 10%. К слову, новая версия компилятора Intel C++ 8.0 набор инструкций SSE3 поддерживает, а это значит, что появление и других различных программ, задействующих инструкции SSE3, не за горами.
Планы
Итак, основная идея, которую преследовали инженеры Intel при разработке нового процессорного ядра Prescott, состояла в создании процессора, который будет масштабироваться по тактовой частоте еще лучше, чем его предшественники. Однако, несмотря на это, максимальная тактовая частота процессоров Prescott, выпущенных сегодня составляет всего лишь 3.4 ГГц. При этом Intel утверждает, что частоты Prescott могут быть доведены в следующем году до 4.5 ГГц.
Согласно планам компании, ядро Prescott будет являться основой процессоров Pentium 4 в течение ближайшего года или чуть более длительного периода времени. За это время Intel будет постепенно расходовать частотный потенциал нового ядра. Вот так выглядят планы компании по представлению новых моделей процессоров линейки Pentium 4:

Во втором квартале этого года будут представлены процессоры с частотой 3.6 ГГц, в третьем квартале выйдут Pentium 4 3.8 ГГц, к концу же 2004 году доступны будут уже процессоры с частотой 4 ГГц. В следующем году ядро Prescott продолжит рост своих тактовых частот до тех пор, пока на смену ему не придет новое ядро, Tejas. Tejas, хотя и будет производиться по тому же самому техпроцессу (возможно, с некоторыми изменениями), что и Prescott, будет иметь дополнительные усовершенствования, позволяющие осуществить очередной рывок в тактовых частотах. Очевидно, что в очередной раз будет удлинен конвейер, а также вновь выполнен цикл работ по уменьшению отрицательного влияния этого изменения: увеличены объемы кеш-памяти, улучшен механизм предсказания переходов и т.п.
Переведена на использование 90-нанометрового ядра будет и линейка дешевых процессоров Celeron. Первые Celeron, в основе которых будет лежать ядро Prescott, появятся на рынке во втором квартале этого года. Для использования в дешевых моделях процессоров ядро Prescott будет несколько урезано: объем кеша второго уровня Celeron на 90 нм ядре составит 256 Кбайт, частота шины этих процессоров будет равняться 533 МГц, а технология Hyper-Threading будет просто отключена. Также, отставать от своих старших собратьев Pentium 4 процессоры линейки Celeron будут и по тактовой частоте. Например, первые выходящие во втором квартале процессоры Celeron с ядром Prescott будут иметь максимальную частоту 3.06 ГГц.
Говоря о планах Intel на ближайший год, необходимо упомянуть и о совместимости существующих материнских плат с новыми и будущими моделями Prescott. С сожалением мы должны констатировать, что последней моделью процессоров Prescott, совместимой с современными материнскими платами является анонсированный сегодня процессор с частотой 3.4 ГГц. Несмотря на то, что напряжение питания Prescott по сравнению с Northwood понизилось до 1.25-1.4В, ток, необходимый для питания этого CPU, достаточно велик и не уступает току, необходимому для питания Northwood с такой же частотой. Современные материнские платы изначально не рассчитанные на поддержку столь прожорливых процессоров попросту не могут выдавать токи, необходимые для питания процессоров с частотами выше 3.4 ГГц. В связи с этим, чтобы не создавать дополнительных проблем с выяснением совместимости новых процессоров Pentium 4 и старых материнских плат, все процессоры с частотой 3.6 ГГц и выше будут выпускаться для другого процессорного гнезда, известного как LGA 775. Материнские платы, предназначенные для LGA 775 процессоров, появятся во втором квартале одновременно с анонсом Pentium 4 3.6 ГГц, который в версии для Socket 478 выпускаться не будет. Также, вместе с новым процессорным гнездом на рынке появятся и новые наборы системной логики, однако это – тема для совсем другого рассказа.
В заключение разговора о ближайших планах Intel нельзя не затронуть вопрос относительно 64-битных расширений архитектуры IA32. До недавнего времени Intel отрицала возможность появления 64-битных расширений, подобных x86-64 от AMD, в своих IA32 процессорах. Однако не так давно позиция компании стала заметно гибче: теперь её представители говорят о том, что 64-битные расширения могут быть введены, но только тогда, когда на рынке появится программное обеспечение, способное использовать эту новую возможность. Учитывая то, что 64-битная пользовательская операционная система Windows XP выйдет в середине этого года, можно ожидать, что 64-битные расширения в процессорах с ядром Prescott уже есть, однако они деактивированы до поры до времени. Таким образом, отрицать возможность появления на рынке x86-64 процессоров от Intel в течение ближайшего года явно не следует. Впрочем, и строить какие-то прогнозы на этот счет пока явно преждевременно.
Температурный режим и разгон
Температурный режим новых процессоров на ядре Prescott – очень "горячая" тема, поскольку при создании этого CPU Intel столкнулась с проблемой больших токов утечки, в конечном итоге выливающихся в чрезмерное энергопотребление и тепловыделение. Процессоры с ядром Prescott, хотя и производится по более совершенному техпроцессу, и имеют меньшее напряжение питания ядра, даже потребовали выпуска обновленных требований к дизайну материнских плат и модуля питания процессора – Prescott FMB 1.5. Более того, CPU с частотой свыше 3.4 ГГц с современными платами не совместимы как раз из-за высокого энергопотребления.
Вместе с этим Intel утверждает, что процессоры Prescott с частотами до 3.4 ГГц совместимы со всеми Socket 478 платами, поддерживающими старшие версии Pentium 4 на ядре Northwood. Единственное, что требуется от производителей – это обновление BIOS для правильного определения новых процессоров. К кулерам, совместимым с Prescott, Intel также не предъявляет никаких особенных требований.
И, тем не менее, тепловыделение Prescott превышает тепловыделение процессоров с ядром Northwood. Например, ниже мы приводим таблицу с величинами типового тепловыделения (TDP) процессоров на ядре Northwood и Prescott, а также процессоров Intel Pentium 4 Extreme Edition:

Как мы видим, несмотря на то, что текущая ревизия Prescott уже третья по счету, а предыдущие были отвергнуты в частности и из-за высокого тепловыделения, серийные процессоры Prescott оказываются очень "горячими" даже по сравнению с Pentium 4 Extreme Edition, состоящими из гораздо большего числа транзисторов. Таким образом, температурный режим систем на базе Prescott станет гораздо более суровым.
Впрочем, давайте посмотрим на практический аспект этой проблемы. Мы протестировали реальные температуры трех процессоров: Pentium 4 на ядре Prescott, Pentium 4 на ядре Northwood и Pentium 4 Extreme Edition, функционирующих на частоте 3.2 ГГц. Для тестирования мы использовали один и тот же кулер из коробочной поставки этих процессоров (коробочная поставка всех трех этих процессоров включает одинаковый кулер), показания снимались со встроенного в кристалл CPU датчика.

Измерялась минимальная температура процессора в состоянии покоя и максимальная температура процессора, достигаемая при прогреве CPU специализированными утилитами:

Дополнительные комментарии к этим цифрам вряд ли нужны. В работе процессоры на ядре Prescott прогреваются гораздо сильнее, чем их предшественники. Заметьте, мы измеряли температуру процессоров на открытом стенде, что же будет с Prescott после помещения его в корпус, даже представить себе страшно.
В итоге, совершенно понятно, что Prescott – это самый горячий x86 процессор на сегодняшний день. Приобретая системы на базе этого CPU, данный факт следует иметь в виду. Более того, в связи с высокой температурой Prescott, Intel ввела дополнительные требования для производителей корпусов и сборщиков систем. Суть этих требований заключается в необходимости обеспечения низкой температуры воздуха возле процессора. И мы можем только подтвердить: при эксплуатации Prescott вопросам его охлаждения следует уделять самое пристальное внимание.
Помимо измерения температуры процессора Prescott, мы провели исследование и его разгонных качеств. Такой эксперимент позволит нам сделать выводы о частотном потенциале существующего степпинга C0 ядра Prescott. Для проведения этого эксперимента мы использовали процессор Pentium 4 на ядре Prescott, имеющий штатную частоту 3.2 ГГц. Мы не стали применять никакие специальные устройства для охлаждения, которое в нашем случае осуществлялось обычным боксовым кулером. Для достижения лучших результатов напряжение питания процессора было повышено до 1.475В.
В процессе разгона нам удалось поднять частоту FSB со штатных 200 до 225 МГц. Таким образом, процессор был разогнан до 3.6 ГГц.

Впечатляющим этот результат назвать вряд ли возможно. Особенно, если учесть тот факт, что Intel говорит о предельных частотах Prescott порядка 4.5 ГГц. Однако следует иметь в виду, что пока мы имеем дело с одним из первых степпингов этого процессора. Со временем технологический процесс будет усовершенствован и последующие ревизии ядра, которые начнут применяться уже в LGA 775 версиях Prescott, будут иметь гораздо больший разгонный потенциал.
Кроме того, необходимо отметить, что лучших результатов при разгоне можно было бы достигнуть, применив более прогрессивные методы охлаждения. Работая на частоте 3.6 ГГц, наш процессор нагревался до 68-70 градусов. Предельная же температура Tcase для процессоров на ядре Prescott составляет 73.5 градуса. Таким образом, становится очевидно, что разгон был ограничен именно резко возрастающей температурой процессорного ядра при разгоне. Поэтому, экстремальные оверклокеры, использующие водяные или криогенные системы для охлаждения процессоров могут получать гораздо более высокие результаты при оверклокинге CPU на новом ядре Prescott.
Немного тестов производительности
Завершая нашу ознакомительную статью, мы решили привести небольшое количество результатов тестов, позволяющие судить о производительности процессоров основанных на новом ядре Prescott. В качестве тестового приложения был выбран популярный пакет SiSoft Sandra 2004, поскольку данный пакет имеет несколько простых алгоритмов для измерения производительности, способных задействовать, или не задействовать различные функциональные блоки процессора по желанию пользователя. Кроме того, тесты, входящие в этот пакет просты настолько, что скорость их работы практически не зависит ни от объемов и скорости кеш-памяти второго уровня, ни от подсистемы памяти используемой в системе. То есть, влияние на производительность в этом тесте компонентов системы, отличных от собственно CPU, полностью отсутствует.
В тестах принимали участие процессоры Pentium 4 (Prescott) и Pentium 4 (Northwood), работающие на частоте 3.2 ГГц. Ниже приводятся результаты бенчмарка, входящего в пакет SiSoft Sandra 2004, измеряющего производительность процессоров при построении множества Мандельброта.
Мы не будем проводить глубокий анализ полученных результатов, поскольку сами они носят "оценочный" характер. Подробное же исследование производительности процессоров на ядре Prescott в большом количестве тестов – это тема другого материала. Здесь мы лишь отметим, что скорость функциональных блоков, отвечающих за выполнение FP/MMX/SSE/SSE2 инструкций в Prescott, не выросла по сравнению с Northwood. Более низкие результаты, показываемые Prescott при измерении производительности FP/MMX/SSE/SSE2 блока, объясняются в первую очередь возросшей латентностью L1 кеша. Заметим при этом, что скорость, показываемая Prescott в этом тесте при использовании мощностей ALU, больше соответствующей скорости Northwood. Это объясняется описанными выше усовершенствованиями в архитектуре этого процессора и в первую очередь ускорением выполнения умножений, играющих важную роль при построении множества Мандельброта, .
Выводы
В рамках данного материала мы рассмотрели основные черты нового ядра процессоров Pentium 4, имеющего кодовое имя Prescott. Хотя данное ядро и основывается на архитектуре NetBurst, в Prescott можно узреть большое число изменений по сравнению с предшественником Northwood. Анализ характера этих изменений показывает, что в первую очередь речь идет о том, чтобы процессоры Prescott были готовы покорить новые рубежи тактовой частоты. Согласно имеющимся данным, предельная частота процессоров на ядре Prescott составит 4.5 ГГц.
Несмотря на то, что в Prescott можно обнаружить много нововведений, призванных поднять производительность этого решения, например увеличенные размеры кеша первого уровня для данных и кеша второго уровня, быстродействие CPU на этом ядре вряд ли совершит качественный скачок по сравнению с быстродействием предшествующих процессоров с NetBurst архитектурой. Дело в том, что для достижения более высоких тактовых частот в Prescott исполнительный конвейер был удлинен более чем в полтора раза, и поэтому нововведения, положительно влияющие на быстродействие, скорее служат для компенсации отрицательного эффекта от удлиненного конвейера. Кроме того, вместе с увеличением объема кеш-памяти возросла и латентность кешей обоих уровней, что также отрицательно может сказываться на производительности процессора в некоторых задачах.
Среди усовершенствований, положительно влияющих на скорость работы Prescott, следует отметить в первую очередь улучшенное предсказание переходов, усовершенствованную предвыборку данных и увеличенную скорость исполнения некоторых целочисленных операций. Кроме того, добавление в процессор тринадцати новых инструкций также способно увеличить удобство написания программ для Prescott и их скорость работы в долгосрочной перспективе.
К сказанному остается только добавить, что огромным "потребительским" минусом Prescott, не имеющим прямого отношения к его архитектуре, является сильно возросшее тепловыделение по сравнению со старыми решениями, что требует разработки новых материнских плат и систем охлаждения для Prescott с частотами выше 3.4 ГГц.
На этом предварительное знакомство с Prescott можно считать оконченным, более же глубокий анализ нового ядра нас ожидает в ближайшем будущем. Мы же приглашаем читателей перейти к ознакомлению с нашим следующим материалом, в котором мы рассматриваем производительность новых и старых процессоров от Intel и AMD в большом числе реальных приложений.



© 1998-2023 fcenter.ru | Россия
© 1998-2023 fcenter.ru | Россия